![[논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F5Ainn%2FbtrdJ3ECLYF%2FeV7LKoBsLXDKW8xnE4m3q1%2Fimg.png)

이번 논문은 Video Inpainting에 관한 논문이다. Video Inpainting 논문 중에 가장 잘 알려진 논문 중에 하나라고 할 수 있다. 영상의 누락된 영역을 채우는 것을 목표로 하는 Video Inpainting 은 영상 콘텐츠의 정확한 공간적, 시간적 일관성을 보존하기 어려워 여전히 어려운 문제로 남아있다.
본 논문에서는 새로운 flow를 guide하는 inpainting 방법을 제안한다. 각 프레임의 RGB 픽셀을 직접 채우는 대신 비디오 인패인팅을 픽셀 propagation 문제로 생각하기 때문에 새롭게 설계된 Deep Flow Completion 네트워크를 사용하여 비디오 프레임 전반에 걸쳐 공간적이고 시간적으로 Deep Flow Completion 네트워크는 flow field를 완성한다. 이를 위해 대략적인 fine-tuning을 따르는 동시에 Hard Flow Example Mining을 통해 품질을 더욱 향상시키고자 한다. 그리고 완성된 flow guide에 따라 누락된 비디오 영역을 정확하게 채우는 것을 목표로 한다. 본 논문의 방법은 DAVIS 와 YouTube-VOS 데이터셋에서 질적, 양적으로 평가되어 인페인팅 품질과 속도 측면에서 최첨단 성능을 달성한다.
Previous Method Limitation
기존의 video inpainting은 전통적인 image inpainting pipeline을 따른다. patch-based optimization task 로 spatial 또는 spatial-temporal patch를 통해 missing region을 채우면서 minimization problem (?) 을 해결할 수 있다. 하지만, 2가지 단점이 존자해는데 하나는 missing region안에서 smooth 하고 homogenous motion field을 가정할 수 있지만 복잡한 모션들을 가진 비디오는 다루지 못한다. 두번째론 optimization based method의 계산 복잡도가 높기 때문에 이러한 방법들은 실제 응용에 적용할 수 없다.
Proposed Method
본 논문에서 제시하는 프레임워크에는 두가지 단계로 나눠진다.
Phrase 1. To complete the missing flow (누락된 흐름을 완료하는 것.)
Phrase 2. To propagate pixels with the guidance of completed flow field. (완료된 flow field의 가이드로 픽셀을 전파하는 것.)
1. Methodology
1. To complete missing flow => Deep Flow Completion Network 사용.
2. Flow 가 얻어지면 propagate pixels with the guidance of completed flow fields.
3. 보편적인 image inpainting network는 결국 남아있는 region을 완성하는데 쓰임.
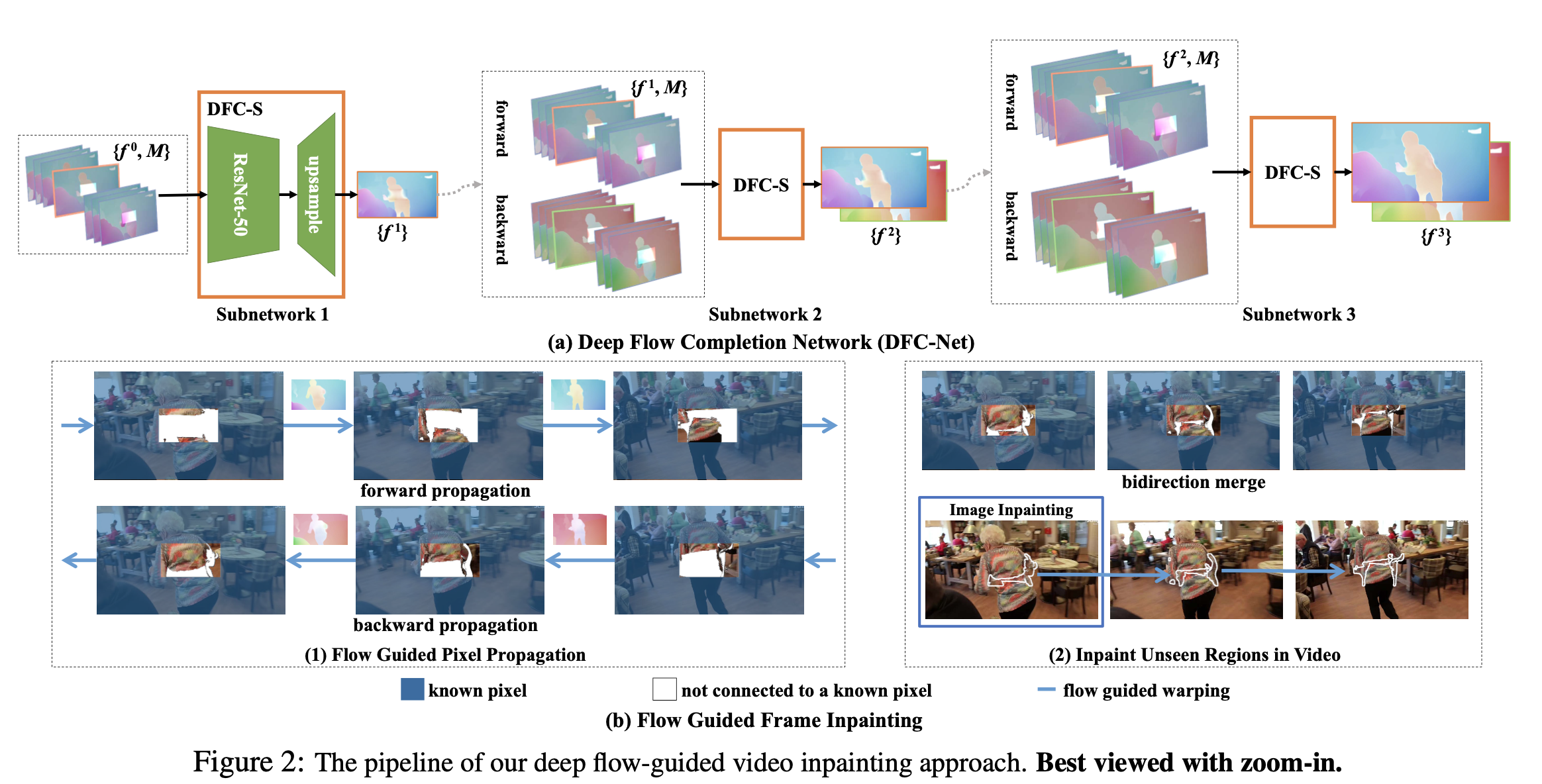
Deep Flow Completion Subnetwork (DFC-S)
첫번째 DFC-S에 2가지 input 제공함. 하나는 연속적인 frames으로 부터의 flow map 합성본과 다른 하나는 binary mask의 연관된 sequence이다. 쉽게 말하면 연속적인 frames의 flow map 합성본과 흑백 mask다.
DFC-S의 결과값은 중간 frame의 완성된 flow field 이다. 다음은 i번째와 i+1번째 frame사이의 initial flow이다. M i -> i+1 은 마스크를 가르킨다. 우리는 처음에 FlowNet 2.0을 사용하여 flow를 추출하고, boundary inward의 알려진 value를 smoothly interpolating 하면서 f*0안에 있는 모든 구멍을 초기화 시킨다. 첫번째 DFC-S input은 33 channel으로 들어가야 하기 때문에 (11 flow maps each for the x and y direction flows, and 11 binary masks.) input channel을 수정했다. 그 다음 두번째 세번째 DFC-S를 위해 인풋과 아웃풋은 다르다. RESNet이 backbone 이며, upsampling module은 세개의 다른 convolution으로 구성되었으며, relu와 upsampling layer들은 예측을 확장하는데 더해졌다. 예측에서 flow field로 곱해지기 위해선, upsampling module에서 마지막 activation function 을 삭제했다.

Deep Flow Completion Network(DFC-Net)
우선, 비디오 안에서 optical flow를 채우기 위해서 DFC-Net을 디자인 했다. DFC-Net은 앞서 설명한 DFC-S 세개의 유사한 flow sub network로 구성된다. 다음 figure에서 볼 수 있듯이, 두가지 실험 셋팅을 두었다. foreground object removal은 이미지 안의 세그먼트 단위의 물체를 삭제하는 테스크이다. 본 논문에서 foreground object removal 테스크는 DAVIS 데이터셋으로 진행하였다. (YouTube 데이터 셋은 segment annotation이 없기 때문)

Refine Flow by Stacking
전체적인 pipeline은 다음과 같다. 원래 이미지 사이즈와 비교했을때, 각 subnetwork에 들어가는 인풋은 각각 1/2, 3/2, 1로 resize되어 들어가게 된다. 그 이유는 더 작은 구멍일 수록 missing flow를 완성한느데 더 쉽기 때문이다. 그래서 첫번째로 좋은 초기 결과를 얻기 위해서 첫번째 input frame 의 사이즈를 1/2로 줄였다. 그 뒤로 더 자세한 부분을 캡쳐하기 위해서 점차적으로 두번째, 세번째 subnetwork를 확장시켰다.
첫번째 subnet에서 coarse flow을 얻은 후에, 두번째 subnetwork는 추가 흐름 개선에 포커스를 맞춘다. 더 나은 flow field를 align 시키기 위해, the forward 와 backward flow들을 두번째 subnetwork안에서 함께 refine (?) 시킨다. f1은 first subnetwork에 의해 coarse flow field 가 생성된다고 가정한다.
두번째 subnetwork는 첫번째와 같은 구조를 공유한다. 하지만, Input과 output은 다르다. 마지막으로, 2번째 subnetwork에서 나온 예측값을 확장하고, 3번째 subnetwork로 fed한다. 이 3가지 subnetwork가 stacking 된 구조로 이뤄진 셈이다.
Training
학습을 위해, 각 video sequence을 위해, 랜덤하게 missing region을 채운다. 가장 최적의 목표(training loss)는 l1 distance을 최소화하는 것이다. 세가지 subnetwork은 각각 처음 pre-trained하고 end-to-end 방법으로 fine tuned한다.

Hard Flow Example Mining(HFEM)
smooth region 과 boundary region 사이에 training samples의 갯수 안에서 큰 bias 가 존재. 실험에서, l1 loss를 직접 사용하면 일반적으로 훈련 과정이 부드러운 영역에 의해 지배되고 예측의 경계 영역이 흐려지는 불균형 문제로 이어진다는 것을 관찰한다. 더 나쁜 것은 흐름의 가장자리가 잘못되면 후속 전파 단계에서 심각한 아티팩트가 발생할 수 있다는 점입니다. 이 issue를 극복하기 위해, hard flow example mining mechanism을 제안한다. hard flow example mining mechanism을 가진 L1 loss 는 다음과 같이 정의한다. 이 mechanism을 통해서 모델은 더 sharp 한 boundary 를 생성하는데 포커스를 할 수 있데 배운다.
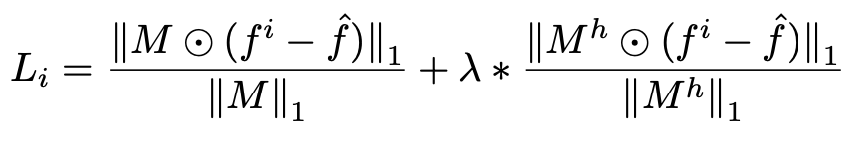
Flow Guided Pixel Propagation
추정한 flow가 어떤 위치에서는 정확하지 않는 경우가 있기 때문에 첫번째로 flow의 유효성을 체크할 필요가 있다. consistency을 확인 후에, 유효한 추정된 flow를 기반으로 missing region을 채우기 위해 모든 pixel들은 양방향으로 propagation이 된다. 특히 알 수 없는 픽셀이 앞으로 알려진 픽셀과 뒤로 알려진 픽셀로 모두 연결되면 픽셀 값의 선형 조합으로 채워지며, 픽셀 값의 가중치는 알 수 없는 픽셀과 알려진 픽셀 사이의 거리에 반비례한다.
2. Result
fixed region (mask) inpainting의 quantitive result

* PSNR : 영상 손실로 인하여 화질 손실 정보를 평가할때 사용하는 지표. mse 가 작을 수록 psnr 값이 큼. (psnr이 클수록 원본과 비교하여 손실이 많이 없다는 뜻)
* SSIM : 원본 영상에 대한 유사도를 평가. 1에 가까울 수록 좋음.

Reference
Deep Flow Guided Video Inpainting : https://arxiv.org/pdf/1905.02884.pdf
pytorch code : https://github.com/nbei/Deep-Flow-Guided-Video-Inpainting
'Artificial Intelligence > Research Paper 리뷰 📖' 카테고리의 다른 글
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
-
![[논문 리뷰] RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoIzJb%2FbtrfHejtiz1%2FpRu9bkCLsa3wHkdkTWB461%2Fimg.png) [논문 리뷰] RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition2021.09.22
[논문 리뷰] RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition2021.09.22 -
![[논문 리뷰] Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN_ICCV 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcptmCz%2Fbtrftor7NrV%2FBaxJg0TrZ0K5cOGueCFCh0%2Fimg.png) [논문 리뷰] Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN_ICCV 20192021.09.18
[논문 리뷰] Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN_ICCV 20192021.09.18 -
![[논문 리뷰] Domain Adaptation](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcuMgzz%2FbtrcLAJ0Pb3%2FmRMo7gOjzdBklTtHxpCBV1%2Fimg.jpg) [논문 리뷰] Domain Adaptation2021.08.31
[논문 리뷰] Domain Adaptation2021.08.31 -
![[논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FsZygV%2Fbtq9C8WMrO5%2FACy71dqhuxNrWC6Tzyn9Mk%2Fimg.png) [논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)2021.07.15
[논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)2021.07.15