![[논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FsZygV%2Fbtq9C8WMrO5%2FACy71dqhuxNrWC6Tzyn9Mk%2Fimg.png)

이번 논문은 GAN의 parameter finetuning과 discriminator feature loss를 이용하여 low level vision task를 보다 nature image(target image)에 가깝게 Restoration(복구)하고 다양한 이미지 Manipulation(조작)을 가능하게 하는 Deep Generative Prior에 관한 논문이다.
기존 방법의 한계점
기존의 연구인 DIP (Deep Image Prior) 는 low-level image statistics은 잘 캡쳐 했지만, rich image semantics(color, spatial coherence, textures, and high-level concepts)을 캡처하는 데에는 여전히 gap이 존재했다.
제안하는 DGP의 장점
1. DGP는 기존 연구보다 missing semantics(색깔 이나 패치, 해상도, 다양한 degraded images)복구가 우수함.
2. random jittering, image morphing, category transfer 를 포함한 다양한 이미지 조작 가능.
3. 매우 유연한 복구 및 조작은 현재 존재하는 GAN-Inversion 방법의 가정을 통해 가능하게 함.
4. 특히, GAN 내 discriminator가 파악한 feature distance로 Generator를 순차적으로 fine-tuning 할 수 있음.
본 논문에서 제안하는 방법은 구현하기 쉽고 실질적인 변경 사항을 통해 reconstruction을 보존하여 nature image의 매니폴드로 유지함으로써 실제 영상을 보다 정확하고 충실하게 제너레이팅할 수 있다고 주장한다.
1. Introdution
기존의 image prior model은 nature image의 확실한 통계를 캡처하는 것에 목적을 두었지만 , 최근에는 일반적인 prior를 찾는 것에 대한 관심이 급증하고 있다. 예를 들어, DIP에 대한 중요한 연구는 무작위로 초기화되는 CNN의 구조가 텍스처 레벨 이미지를 사전에 암시적으로 캡처한다는 것을 보여주었고, 따라서 손상된 이미지를 재구성하기 위해 이를 fine tuning 함으로써 복원에 사용할 수 있다.

본 연구에서는 한 단계 더 나아가서 , 어떻게 large scale한 nature image에 학습된 영향력 있는 GAN을 만들 수 있을까 하는 질문에서 시작된다. GAN은 reconstruction을 할 때 최대한 natural image manifold에 따르는 이미지를 생성할 수 있어야 한다. 이에 GAN-Inversion이 효과적인 옵션이라고 말한다.
2. Related Work
Image Prior
이미지의 prior라 하면 nature image의 다양한 통계치를 묘사한 것을 의미. 이미지의 분포라고 생각할 수 있다.
Image Restoration and Manipulation
대표적으로 image colorization, image inpainting, super resolution, adverserial defence, semantic manipulation이 있음. 본 논문에서는 DGP를 이용하여 위 다섯 가지 task를 모두 수행했음,
GAN - Inversion
원래 GAN이 어떠한 이미지를 생성하기 위해선 latent space 상의 분포 중 랜덤 샘플링된 z값이 인풋으로 들어가서 z에 따른 이미지를 생성한다. 하지만 GAN Inversion은 반대죠. 주어진 실제 이미지 real image x를 복구하기 위한 최상의 latent space z*를 구하는 방법이다. 한편으로 GAN-Inversion은 여전히 전체적인 데이터 분포를 찾지 못하고 한 곳의 분포만 찾아 데이터를 생성하는 mode collapse 문제와 제한된 generator의 용량에 따른 어려움이 있으며 원하는 데이터 매니폴드 캡쳐 능력에 영향을 미친다. 또한 더 중요한 한계는 generator가 고정되어 있을 때, GAN은 불가피하게 training 분포에 의해 제한되고, 복잡한 이미지를 충실히 재구성할 수 없다는 것에 있다.
대략적인(approximated) 매니폴드와 실제(actual) 매니폴드 사이의 차이에도 불구하고 GAN generator는 여전히 풍부한 nature image 통계를 캡처한다. 앞서 언급한 한계를 피하면서 이러한 통계를 활용하기 위해, 본 논문에서는 GAN의 prior 활용을 위해 보다 안정적이고 실용적인 reconstruction 공식을 제시한다.
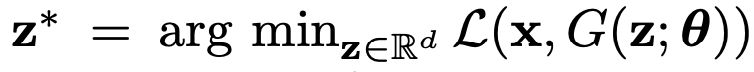
3. Methodology
Main Contribution 1
첫번째는 target 이미지에서 즉시 generator param 세타와 z를 fine-tuning 할 수 있도록 하는 것.
기존 DIP에서 기준 loss 인 perceptual loss 와 mean squared error를 사용하는 것이 원래의 중요한 prior를 잃어버릴 수 있다고 말한다. 그래서 다음과 같은 새로운 loss를 제안한다. 이때 loss 는 세타와 z를 최소로하는 L2 distance loss를 사용한다.

generator에 들어가는 최적의 z와 세타를 구하기 위해 nature image x를 degraded시킨 이미지와 generator에서 나온 생성된 image G를 degraded 시킨 이미지 사이의 loss를 최소로 하는 update param 값으로 정의한다. 그리고 다시 기존의 generator param 값을 update param 값으로 generator에 넣어서 두 이미지가 비슷해 지도록 반복하며 학습시킨다.

Main Contribution 2
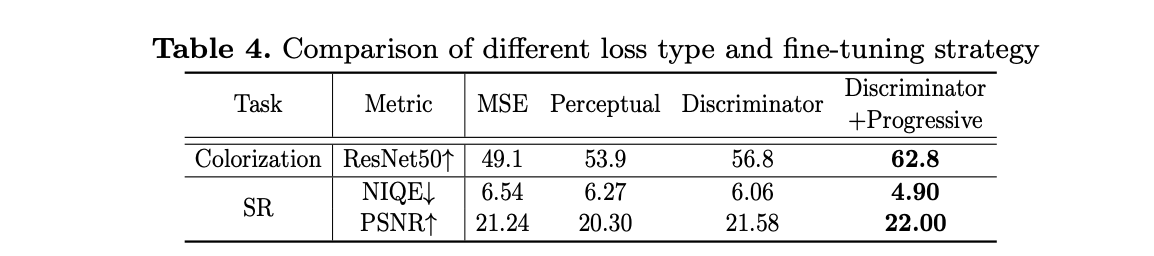
두 번째 아이디어는 효과적인 reconstruction strategy를 제안한다. 가짜와 진짜를 판별하는 discriminator를 진짜의 feature와 생성된 데이터의 feature 사이의 거리까지도 고려하여 학습. Discriminator는 생성된 이미지와 타깃 이미지 사이의 feature space상의 거리를 또 다른 loss로 정의한다. 이때 L1 distance로 측정하며, D(x1, i)는 타깃 이미지 x의 i번째 block 상의 feature를 리턴한다. 이와 동일하게 D(x2,i)는 제너레이팅 된 이미지의 i 번째 block 상의 feature일 것이다.
1) Feature matching loss from the coupled discriminator

제안한 방법: feature matching loss based on L1 distance.
generator는 discriminator에 의해 제공된 gradient를 통해 많고 다양한 natural images를 모방하도록 최적화한다. discriminator가 오리지널 param 구조를 잘 보존하기 때문에 다른 distance metric보다 단일 이미지에 일치하도록 discriminator를 가지는 것이 효과적이라고 말한다. 그러므로 discrimator로부터 feature matching loss를 도출하면 natural images에서 유지되도록 reconstruction을 유지할 수 있다. 즉, 기존의 "가짜와 진짜를 판별하는 discriminator를 진짜의 feature와 생성된 데이터의 feature 사이의 거리까지도 고려하여 학습시키겠다." 라는 의미로 해석할 수 있다.
2) Progressive reconstruction
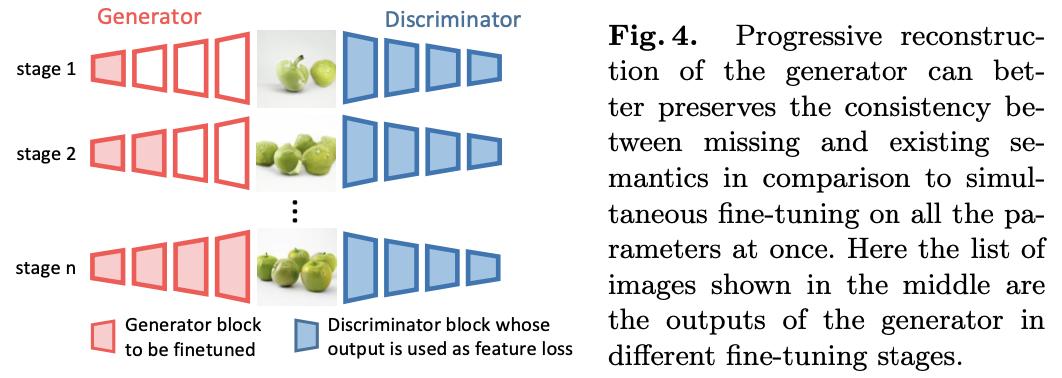
이전 문제점 : generator의 모든 파라미터를 한방에 fine-tuning 하는 것은 "정보 잔상"(: degraded 된 이미지를 reconstruction할 때 누락된 sementantics(e.g. 색상..,) 이 내용과 함께 자연스럽게 변경되지 않음) 문제가 발생할 수 있다. 그 이유는 generator의 깊은 층이 high level configuration를 정렬하기 전에 low-level texture와 매치하기 때문이라고 한다.
그래서 제안한 방법이 스테이지별로 점차적(progressive)으로 generator를 shallow layer로 부터 deep layer 까지 점차적으로 fine-tuning하는 전략이다. 이러한 방법은 low-level detail에서 집중했던 것을 점차적으로 high-level에 매칭 하도록 바꾸게 한다.
이렇게 정의된 training loss를 통해 이미지를 생성하게 되는데 다음 그림과 같이 제너레이팅 된 이미지의 파라미터가 업데이트(fine-tuning)되면서 타겟 이미지와 비슷하게 생성되는 것을 볼 수 있다. 이 과정을 본 논문에서는 progressive reconstruction이라고 지칭하였다.

4. Result
본 논문에서는 다양한 application을 가지고 실험 결과를 도출했다.
4.1 Image Restoration 부분
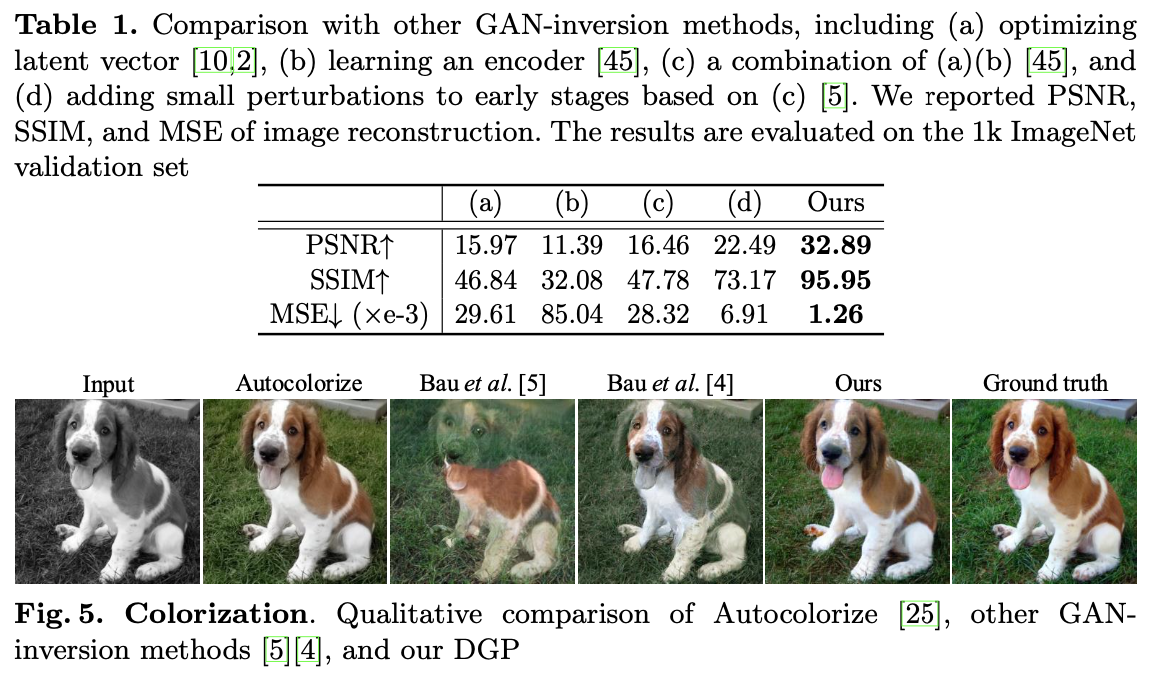
Comparison with other GAN-Inversion 결과
Inpainting 결과


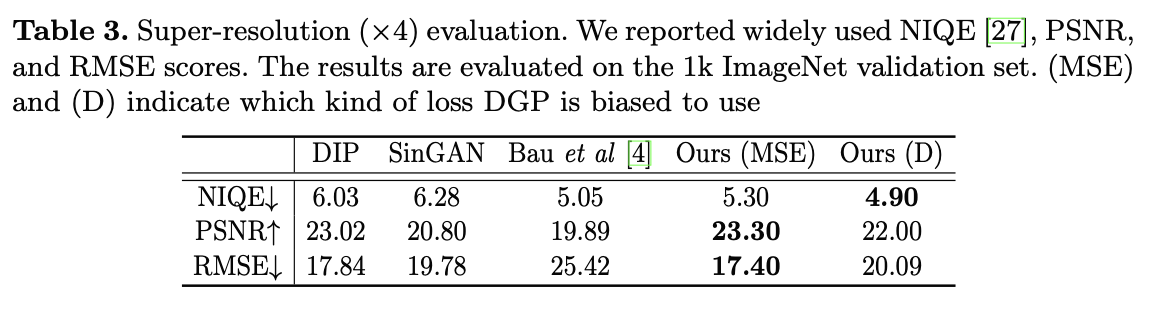
Super-resolution 결과

Colorization 결과

Adversarial defense 결과

4.2 Image Manipulation 부분
Random jittering 결과

Image Morphing 결과

[ Reference ]
- 논문: exploiting deep generative prior for versatile image restoration and manipulation
- ECCV 2020 oral presentation 참조: youtube https://www.youtube.com/watch?v=p7ToqtwfVko
'Artificial Intelligence > Research Paper 리뷰 📖' 카테고리의 다른 글
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
-
![[논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F5Ainn%2FbtrdJ3ECLYF%2FeV7LKoBsLXDKW8xnE4m3q1%2Fimg.png) [논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 20192021.09.05
[논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 20192021.09.05 -
![[논문 리뷰] Domain Adaptation](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcuMgzz%2FbtrcLAJ0Pb3%2FmRMo7gOjzdBklTtHxpCBV1%2Fimg.jpg) [논문 리뷰] Domain Adaptation2021.08.31
[논문 리뷰] Domain Adaptation2021.08.31 -
![[논문리뷰] Stand - Alone Self Attention in Vision Models_NIPS 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FeVMhW6%2Fbtq8lFgpYp8%2FpvJ0gTU31tBdajrWOgyC6K%2Fimg.png) [논문리뷰] Stand - Alone Self Attention in Vision Models_NIPS 20192021.06.28
[논문리뷰] Stand - Alone Self Attention in Vision Models_NIPS 20192021.06.28 -
![[논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FlmGwp%2FbtqUk0kQl4O%2F2MagG6pNM0UvFBR2oySEsk%2Fimg.png) [논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)2021.01.21
[논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)2021.01.21