![[논문리뷰] Stand - Alone Self Attention in Vision Models_NIPS 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FeVMhW6%2Fbtq8lFgpYp8%2FpvJ0gTU31tBdajrWOgyC6K%2Fimg.png)

Self Attention의 시초 논문이자 Google Research, Brain Team 이 발행하여 2019년 NIPS에 어셉된 논문입니다. 처음 Attention 메커니즘은 자연어처리 분야에서 크게 이목을 끌었지만 요즘은 Vision 분야에서 더 핫하고 유용하게 쓰이고 있는 방법입니다.
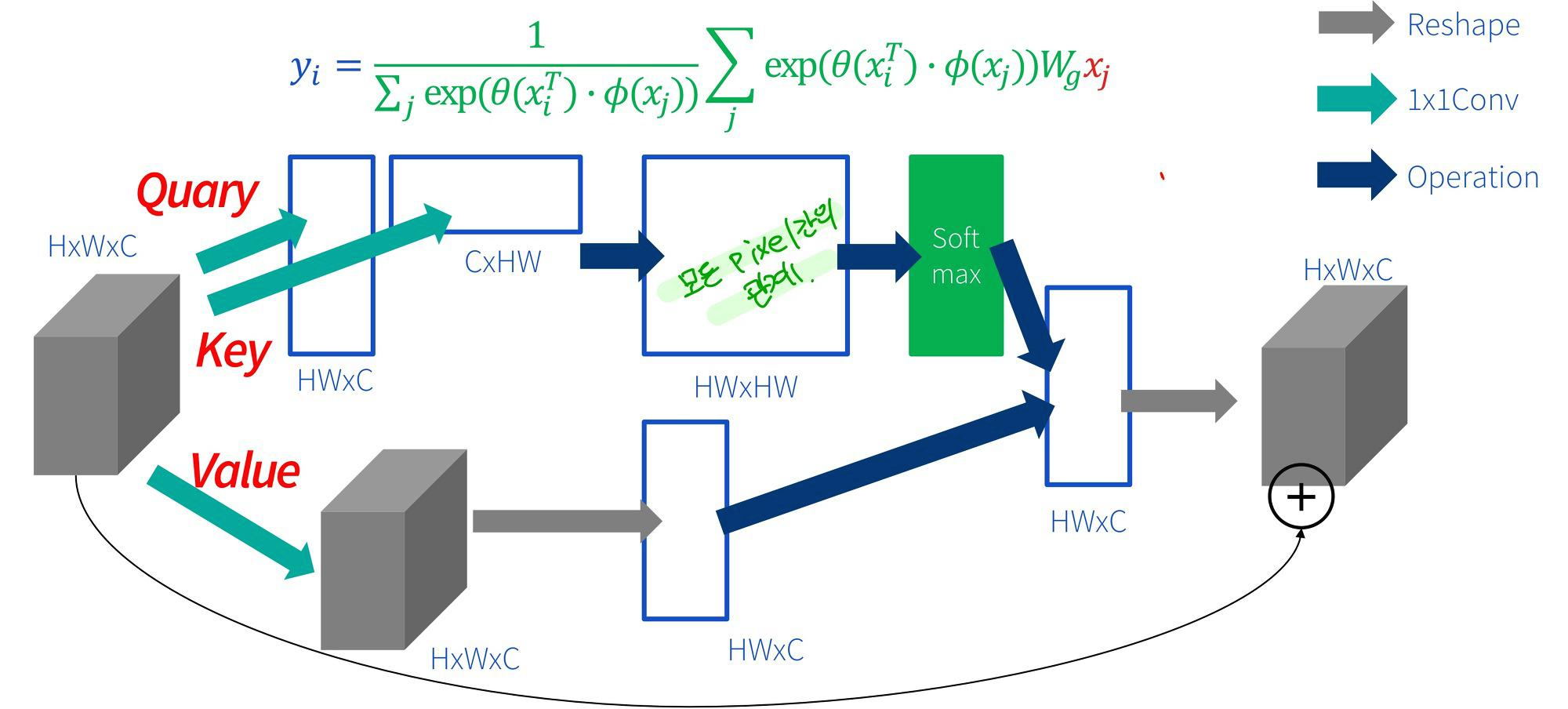
처음 Attention을 이용할때 기존 비전 task에 적용하고자 할때 대부분 Query 와 Key를 곱해서 만든 global attention layer 를 만들어서 기존 CNN 구조에 쌓는 방식이나 encoder decoder 구조로 진행하였습니다. 이 방법은 Query 와 Key를 곱하는 과정에서모든 픽셀간의 관계(=상관성)을 구해야하기 때문에 이미지 픽셀 갯수 n개제곱 만큼의 computaion cost가 많이 발생한다는 단점이 있었습니다.
그 다음, 이후에 나온 개념이 recalibration 개념으로 네트워크가 중요하다고 판단한 부분은 더 곱하고 안 중요한 부분은 죽여서 채널단위로 중요도를 뽑는 Squeeze-and-Excitation Network (CVPR 2018) 논문 입니다. 이 논문에서 소개하는 SEBlock 네트워크는 크게 각 피처맵에 대한 전체 정보를 요약하여 1 * 1 * C 로 만드는 squeeze 부분과 각 피처맵의 중요도를 스케일 해주는 excitation 부분으로 나눠집니다.

이러한 다양한 방법들이 연구되었지만 제가 소개할 논문 stand-Alone Self Attention in Vision Model은 기존의 CNN Convolution layer대신 파라미터 수를 줄이면서 convolution을 대체할 수 있는 local self attention layer 를 제안합니다.
1. INTRODUCTION
그동안 비전 분야 응용분야에서 convolution은 backbone으로 매우 유용했습니다. 하지만, convolution은 큰 receptive field에 대한 스케일링 특성이 좋지 않기 때문에 다시말해 convolution 연산이 localization 이기 때문에 long range interaction을 캡쳐하기에 어렵다는 한계점을 가지고 있습니다. long range interaction 문제는 attention을 사용한 sequence modeling에서 다뤄 왔습니다.
최근에는 전통적인 CNN의 성능을 높이기 위해 차별적인 컴퓨터 비전 모델에 attention 메커니즘을 적용하여 CNN 채널을 변조할 수 있는 Squeeze-and-Excitation Network가 연구 되었습니다. 마찬가지로 spatially-aware attention은 object detection과 image classification 개선을 위한 contextual 정보를 제공하기 위해 CNN 아키텍쳐를 강화시키는데 사용되었습니다. 본 논문에서는 content-based interaction이 비전 모델의 가장 기본적인 역할을 할 수있는지 질문을 한다. 이를 위해 작거나 큰 input 모두에 사용할 수 있는 간단한 local attention layer를 개발합니다. 본 논문의 저자들은 이 독립적인 attention layer를 사용하여 파라미터 수를 줄이고 컴퓨팅 효율성을 유지하면서 object detection과 image classification 에 뛰어난 성능을 가진다고 주장합니다.
2. BACKGROUND
2.1 Convolution
convolution 연산은 source image(local window) 와 filter(learned weight)의 상하좌우 반전을 한 것의 내적곱으로 output을 갖게되는데, 위의 로짓을 보시면 이해하기 쉽습니다. xab는 input image 또는 이전 단의 feature map이고, W는 filter 또는 다른 말로 kernel 입니다. 중요한것은 CNN은 weight sharing 하기 때문에 W은 모든 픽셀 위치 ij를 생성하기 위해 재 사용됩니다. Figure 2는 3*3 convolution의 예시입니다.convolution에 관한 자세한 설명은 링크를 걸어두겠습니다.
[ convolution에 대한 설명 ]


2.2 Self-Attention
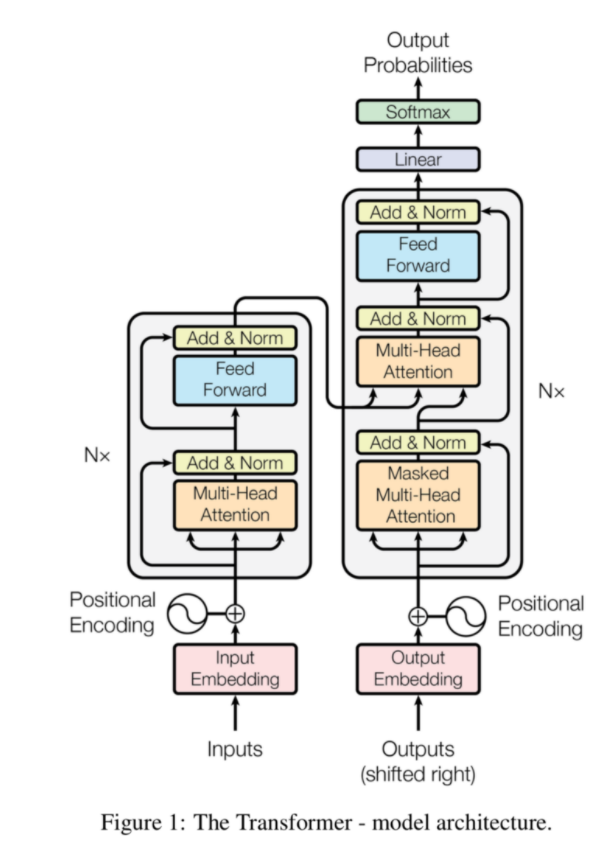
본 논문에서 제안하는 stand alone self attention은 spatial convolution들을 대체하고 fully attentional model을 만듭니다. 처음 self attention 개념이 나왔던 게 attention is all you need 이라는 논문에서 처음 나왔으며 아래의 그림 처럼 Query와 Key 값을 내적하고 스케일링을 한 후 mask를 씌우는데 (이것은 nlp에서만 적용) softmax값을 취한것에 value 값을 내적곱 한 것을 output 값으로 정의합니다.

그렇다면, stand alone self attention 연산이 어떻게 되는지 한번 알아보겠습니다.

1) 파란색이 input이고 input의 중심에 어떤 스칼라 값의 weight가 곱해져서 query값을 만듭니다.
2) input 전체에 어떤 스칼라 값의 weight가 곱해져서 key값을 만듭니다.
3) 이 query값과 key값을 내적한 후 softmax를 취해줍니다. 그러면 각 픽셀의 0~1 사이 의 확률값이 나오게 되겠죠.
4) softmax 취해서 나온 값들과 input에 어떤 weight을 곱해서 나온 value값을 내적을 해줘서 final output 값을 가지게 됩니다.
그렇게 되면 사실 softmax값이 filter 역할을 하게 되면서 convolution layer 와 비슷한 과정을 갖게 됩니다. 하지만, 실질적으로 필요한 weight 값은 총 3개(query, key, value를 만드는데 필요한 weight)가 필요하기 때문에 convolution 연산보다 훨씬 파라미터 수가 줄어듬을 알 수 있습니다.
e.g) 32 * 32 input feature map -> 3*3 filter size * 64 (filter 갯수) -> 64 * 64 output feature map
- convolution param : 3 * 3 (filter size) * 32 (input size) * 64 (output) + 64 (bias)
- self-attention param : 3 (filter size와는 상관없이 무조건 3개) * 32 * 64
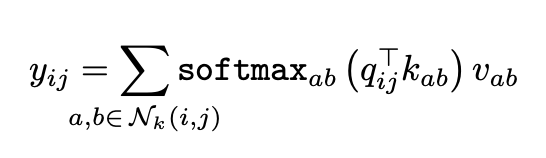
하지만, 현재 프레임처럼 위치 정보는 attention하여 인코딩되지 않기 때문에 비전 작업에 대한 표현성이 제한됩니다.
영상에서 픽셀의 절대 위치(ij)를 기반으로 하는 임베딩을 사용할 수 있지만 상대 위치 임베딩을 사용하면 정확도가 크게 향상됩니다.
대신 2D Relative Position Embedding에 대한 주의, 즉 relative attention이 사용됩니다. relative attention는 각 위치 ab ≤ Nk(i, j)에 대한 ij의 상대적 거리를 정의하는 것으로 시작합니다. 상대적 거리는 여러 치수에 걸쳐 인수분해되므로 각 요소 ab Nk(i, j)는 행 오프셋 a - i와 열 오프셋 b - j의 두 가지 거리로 정의합니다. 행 및 열 오프셋은 각각 1/2d 출력 차원과 함께 내장 ra-i 및 rb-j를 형성합니다. 이러한 spatial relative attention은 다음의 로짓으로 정의됩니다.


3. Fully Attentional Vison Model
이제 local self attention을 어떻게 적용할지에 관한 설명을 해보겠습니다.
3.1 Replacing Spatial Convolution
본 논문에서 제안하는 첫번째 방법은 spatial 한 convolution을 전부 self attention layer로 변경하는 것 입니다.
- 여기서 spatial 한 convolution이란 kernel size(filter size) > 1 을 가지는 convolution을 의미합니다. 다시말해 특별한 정보를 포함하지 않는 1 * 1 convolution을 제외한 convolution을 spatial convolution 이라고 합니다.
- 그리고 spatial downsampling 이 필요한 경우에, attention layer 이후에 stride 2인 2 * 2 average pooling을 합니다.
- ResNet 아키텍쳐를 사용했으며 , 모든 3 * 3 spatial convolution을 self attention 으로 대체하였습니다. (하지만, 이 전략은 최적의 전략이 아닐 수 도 있으며 아키텍쳐 서칭을 통해 더 나은 아키텍쳐를 찾아서 적용한다면 더 좋은 성능을 가질 수 있다고 말합니다,)
3.2 Replacing the Convolutional Stem
본 논문에서 두번째로 제안하는 방법은 CNN 초반 layer, 다시말해 앞단에서 사용하는 layer를 바꾸는 방법입니다. 예를들면 ResNet 같은 경우 , 앞단에 stride 2 인 7 * 7 convolution을 사용하는데, 이것은 edge와 같은 local feature를 추출하는 데 중요한 역할을 합니다. 스템 계층에서 콘텐츠는 개별적으로 정보를 제공하지 않고 spatially correlated RGB 픽셀로 구성됩니다. 이 속성은 edge detector와 같은 유용한 기능을 self attention와 같은 content-based 메커니즘에 학습하기 어렵게 만듭니다.
이는 기존 convolution에 주변 픽셀 정보를 확률로 추가해 준 형태인데, stem layer의 value값을 조금 변형하여 spatial 한 정보를 주기 위한 메커니즘입니다.
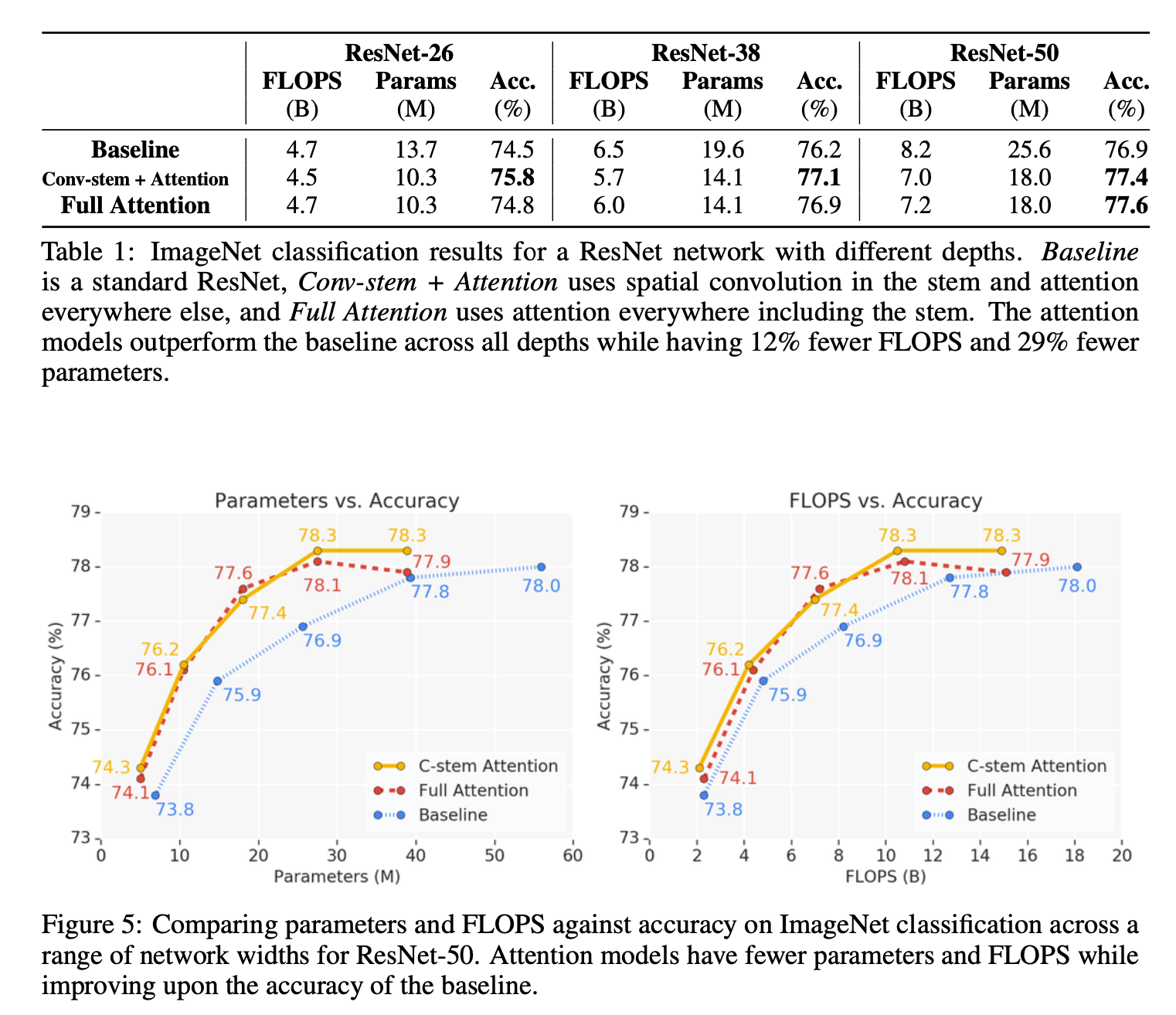
초기 실험에서는 ResNet의 convolution stem을 사용할 때보다 스템의 equation 3에 설명된 attention stem을 사용하는 것이 성능이 떨어지는 것을 확인할 수 있습니다. 하지만, Resnet의 layer가 깊어질수록 attention stem의 성능이 convolution stem보다 미미하게 높아진것을 아래의 표에서 확인할 수 있습니다.

4. Result
[ ImageNet Classification ]
결과를 보면 Attention을 적용한 것이 Baseline인 단일 ResNet 아키텍쳐를 사용했을 때 보다 더 높은 정확도를 가집니다. ResNet-26일때는 Conv-stem + Attention이 좋았지만, layer가 더 쌓인 ResNet-50일때는 attention-stem + Attention(Full attention)이 모든 아키텍처에서 제일 좋은 결과를 가졌음을 알 수 있습니다.
[ Object Detection ]

[References]
- Stand-Alone Self-Attention in Vision Models, Google Brain, NIPS 2019
- Attention is all you need, Vaswani, et al., 2017
- https://towardsdatascience.com/self-attention-in-computer-vision-2782727021f6
- Pytorch code : https://github.com/leaderj1001/Stand-Alone-Self-Attention
'Artificial Intelligence > Research Paper 리뷰 📖' 카테고리의 다른 글
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
-
![[논문 리뷰] Domain Adaptation](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcuMgzz%2FbtrcLAJ0Pb3%2FmRMo7gOjzdBklTtHxpCBV1%2Fimg.jpg) [논문 리뷰] Domain Adaptation2021.08.31
[논문 리뷰] Domain Adaptation2021.08.31 -
![[논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FsZygV%2Fbtq9C8WMrO5%2FACy71dqhuxNrWC6Tzyn9Mk%2Fimg.png) [논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)2021.07.15
[논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)2021.07.15 -
![[논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FlmGwp%2FbtqUk0kQl4O%2F2MagG6pNM0UvFBR2oySEsk%2Fimg.png) [논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)2021.01.21
[논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)2021.01.21 -
![[논문리뷰] Out Of Distribution(OOD) Detection With Computer Vision_Ver.2](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fc8JcYy%2FbtqTcRwP5L0%2Fu8CMjG9kFtbTfLikocDtOK%2Fimg.png) [논문리뷰] Out Of Distribution(OOD) Detection With Computer Vision_Ver.22021.01.12
[논문리뷰] Out Of Distribution(OOD) Detection With Computer Vision_Ver.22021.01.12