![[논문리뷰] Out Of Distribution(OOD) Detection With Computer Vision](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FF5QoP%2FbtqSDvAoL0l%2F35jX6CSkZqakexvyoJRDs1%2Fimg.png)

이상 탐지(Out-Of-Distribution Detection)를 큰 토픽으로 세부적인 다양한 방법을 작은 토픽으로 분류하여 논문 리뷰를 해보도록 하겠다. 제가 가장 관심있는 분야인 만큼 상세히 논문 리뷰를 기록하기 위해 본 블로그에 글로 적게 되었다.
ENHANCING THE RELIABILITY OF OUT-OF-DISTRIBUTION IMAGE DETECTION IN NEURAL NEWORKS. / Shiyu Liang, Yixuan Li, R.Srikant (ICLR 2018)
본 논문에서는 Softmax 로 나온 각 Class의 확률값들을 OOD(out of distribution)와 ID(in-distribution)으로 명확하게 분류하기 위해 몇가지 지표를 제시한다. 이미 학습이 끝난 neural network에 어떠한 추가 학습 없이 간단하면서 효과적으로 out-of-distribution sample들을 찾아낼 수 있다는 점이 가장 큰 장점이며 실제로도 구현하기 쉽다.
1. Temperature Scaling
학습중에는 temperature scaling parameter T를 1로 두고 학습을 진행한 뒤에, test 단계에서 주어진 input의 예측 확률을 구하기 위해 softmax score를 구하기 되는데 이때 각 로짓들을 T로 나눠주는 방식으로 구현이 가능하다. 이를 OOD detection 문제에 적용하면 각 OOD와 ID의 거리를 더 멀어지게 하여 OOD sample을 구별하기 쉽게 도와주는 역할을 한다. 그렇기에 T (hyper parmameter)값을 적절히 조절해서 정해주는 것이 중요하다.

2. Input Preprocessing
temperauter scaling에 따라서 우리는 작은 섭동을 더함으로써 input을 전처리한다. 사인함수 앞의 입실론은 섭동 크기를 의미한다. 이 방법은 작은 섭동이 softmax score를 감소시키기 위해 더해진다. FGSM(Fast Gradient Sign Method)에서 아이디어를 얻었다고 한다. Back propagation을 통해 loss를 증가시키는 방향의 gradient를 계산하여 얻은 perturbation을 input으로 더해준다.
*섭동(perturbation): 딥러닝에서 작은 변화 , 즉 이미지에 적절한 noise를 추가하는 방법 이라고 생각하면 될 것 같다.
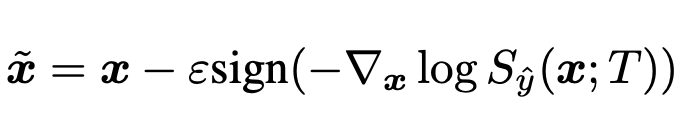
3. Out-of-distribution Detector
이 지표는 이상이라고 판단하기 위한 임계값 지표라고 생각하면 되겠다. image x를 위 2번 equation(Input Preprocessing)에 넣고 전처리가 된 x를 1번 equation(Temperature Scaling)에 넣는다. Temperature Scaling 되어 나온 Softmax Score를 가지고 분류하기 위한 Threshold에 의해 Binary Classification을 한다.

실험 셋팅
본 논문의 실험은 DenseNet 과 Wide ResNet 모델로 실시하였다.
데이터셋은 CIFAR-10과 CIFAR-100으로 실시.
[ DenseNet (Dense-BC) ]
-depth=100
-growth rate k=12
-dropout rate=0
[ wide ResNet (WRN-28-10) ]
-depth=28
-wide=10
-dropout rate=0
ID(In-distribution)과 OOD(Out-Of-Distribution)을 구별하기 위한 OOD dataset을 준비.
OOD dataset : crop되거나 resize되거나한 이미지 데이터. 혹은 Gaussian Noise 나 Uniform한 Noise가 있는 이미지.
평가 지표
1. TPR / FPR
95% TPR(True Positive : True을 True이라고 예측함)일 때의 FPR(False Positive : False를 False라 예측)
95%의 TPR를 가질때 OOD를 ID라고 잘못 예측한(FPR) 확률이라고 해석할 수 있음.
2. Detection Error
TPR이 95%일 때 misclassification 확률.
Pe = 0.5(1-TPR) + 0.5FPR
추가로 논문 내 실험 뒤 섹션에 OOD를 탐지하기 위한 Equation을 분석한 Discussion도 있으니 Equation을 조금 변형해 보고 싶다면 참고하면 좋을 것 같다.
DEEP ANOMALY DETECTION WITH OUTLIER EXPOSURE / Dan Hendrycks, Mantas, .. (ICLR 2019)
OOD 데이터는 학습 데이터의 분포와는 다른 분포를 갖는 데이터를 의미한다. 분류 문제에서 OOD는 학습 데이터에 포함되지 않은 class를 가진 데이터를 의미할 수 도 있다. (e.g. CIFAR-10을 분류하는 모델 입장에서 SVHN 데이터는 OOD 이다.)
본 논문은 outlier에 관한 추가적인 데이터셋을 가지고 학습을 시키는 방법인 OE(Outlier Exposure)을 제시한다. 이 방법은 이상 탐지기가 보이지 않은 이상치들을 탐지하는 것을 가능하게 한다. 학습시에 OOD 데이터를 노출시켜 OOD 모델 성능을 향상시키는 방법론이다. 자연어 처리 분야나 작고 큰 스케일 비젼에서, Outlier Exposure가 상당히 탐지 성능을 향상시킬 것이라고 확신한다. 실제로, 실험을 통해 OE를 적용하였을 때 성능 향상을 보였다.
본 논문은 OOD를 위한 모델에 기존의 D in, D out 데이터에 OE 방법을 적용한 데이터인 D out-oe을 추가하여 학습시켜 성능을 높혔다.
실험은 Image dataset과 Text dataset으로 진행하였다. 다음은 각 데이터에 대한 성능 결과이다. 확실히 OE를 추가하였을 때 성능이 향상된 것을 볼 수 있다.
[Image dataset]

[Text dataset]

본 논문에서 OOD detection 성능을 높이기 위한 D out-oe 데이터 특징은 다음과 같다.
CIFAR-10을 ID한 실험에서 CIFAR 100의 10개의 class 를 D out-oe로 활용했을 때와 30개 class를 D out-oe로 활용했을 때 그 성능 차이 가 7%밖에 나지 않았다. 개수를 늘려도 성능 차이는 별로 없었다.
또한, D out-oe 와 D out-test 는 유사성이 떨어져도 전혀 관계 없었다.
SVHN과 비슷한 이미지인 숫자 이미지 데이터를 사용한 것 보다 아예 관련 없는 자연 이미지를 D out-oe로 사용하는 것이 오히려 성능이 좋았다. 반대로 D out-oe와 D in은 유사성이 있는 경우 성능이 좋았다. 결국, D out-oe는 충분한 다양성이 확보된 D in 과 유사성이 높은 데이터 셋을 사용하는 것이 좋다.
To Be Continue
.
.
'Artificial Intelligence > Research Paper 리뷰 📖' 카테고리의 다른 글
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
-
![[논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FsZygV%2Fbtq9C8WMrO5%2FACy71dqhuxNrWC6Tzyn9Mk%2Fimg.png) [논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)2021.07.15
[논문리뷰] Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation_ECCV 2020(oral paper)2021.07.15 -
![[논문리뷰] Stand - Alone Self Attention in Vision Models_NIPS 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FeVMhW6%2Fbtq8lFgpYp8%2FpvJ0gTU31tBdajrWOgyC6K%2Fimg.png) [논문리뷰] Stand - Alone Self Attention in Vision Models_NIPS 20192021.06.28
[논문리뷰] Stand - Alone Self Attention in Vision Models_NIPS 20192021.06.28 -
![[논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FlmGwp%2FbtqUk0kQl4O%2F2MagG6pNM0UvFBR2oySEsk%2Fimg.png) [논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)2021.01.21
[논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)2021.01.21 -
![[논문리뷰] Out Of Distribution(OOD) Detection With Computer Vision_Ver.2](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fc8JcYy%2FbtqTcRwP5L0%2Fu8CMjG9kFtbTfLikocDtOK%2Fimg.png) [논문리뷰] Out Of Distribution(OOD) Detection With Computer Vision_Ver.22021.01.12
[논문리뷰] Out Of Distribution(OOD) Detection With Computer Vision_Ver.22021.01.12