![[논문 리뷰] RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoIzJb%2FbtrfHejtiz1%2FpRu9bkCLsa3wHkdkTWB461%2Fimg.png)

0. Abstract
본 논문은 convolution layer 대신 mlp layer를 통해서 long range denpency 와 postitional pattern을 캡쳐하는 측면에서 더 효율적이고 나은 결과를 위한 MLP 네트워크를 설계한다. 특히, 본 논문의 저자들은 FC에 local prior를 추가하는 structural re-parameterization technical을 제안한다. 구체적으로, training time 동안 RepMLP 내부의 convolutional layer를 설계하고, test(inference) time에 그것들을 FC로 합친다.
그 결과, CIFAR 데이터셋에서 심플한 MLP 모델은 CNN과 매우 비슷한 performance를 보인다. 일반적인 CNN 모델안에 RepMLP를 추가함으로써, ImageNet dataset에 1.8% 정확도를 향상시켰다. 또한, face recongition 에서 2.9% 를 향상시켰고, 낮은 FLOPS으로 Cityscape dataset 에선 2.3% mIoU를 향상시켰다.
흥미로운 연구 결과는 FC의 global representational capacity(전역적 표현 용량)과 Positional perception (위치 인식)을 컨볼루션의 로컬 이전 작업과 결합하면 변환 불변성(예: 의미론적 분할)이 있는 작업과 정렬된 이미지 및 위치 패턴이 있는 작업에서 모두 더 빠른 속도로 신경망의 성능을 향상시킬 수 있다는 것을 강조한다. (예: 얼굴 인식).
1. Introduction
image 의 locality (어떠한 픽셀은 먼 픽셀 보다 가까운 픽셀, 다시 말해 주변 픽셀에 더 연관성이 있음.)는 CNN을 더 성공적으로 만든다. 이 논문에서는 이러한 귀납적 편견을 local prior라고 부른다.
2. Methodology
Training time RepMLP는 세가지 부분으로 구성된다.
1. Global Perception 역할
partition 사이의 correlation을 각각 partition으로 더한다.
2. Partition Perception 역할
Partition Perception은 long-range dependencies 를 고려한다.
3. Local Perceptron 역할
local perceptron은 몇개의 conv layer와 함께 local pattern을 캡쳐한다.
다음 figure는 Repmlp 구조이다. 여기 N, C, H, W는 batch size, number of input channel, height 그리고 weight 의미. input feature map 은 partition set으로 나눠진다. N = C = 1, H = W, H/w = W/w = 2라고 가정한다. (e.g. 한 channel 은 4 partition으로 나눠진다.) 또한, h와 w는 > 7 이기 때문에 , Local Perceptron은 kernel size 1, 3, 5, 7의 conv layer를 가진다. (이미지 사이즈 보다 커널 즉 필터 사이즈가 클 수 없기 때문) tensor parameter의 모양이 FC 및 conv layer와 함께 표시된다. structural re-parameterization를 통해, conv 및 BN layer가 있는 training time 블록은 3-FC 블록으로 동등하게 변환되며, 이는 test(inference)를 위해 저장되고 사용된다.
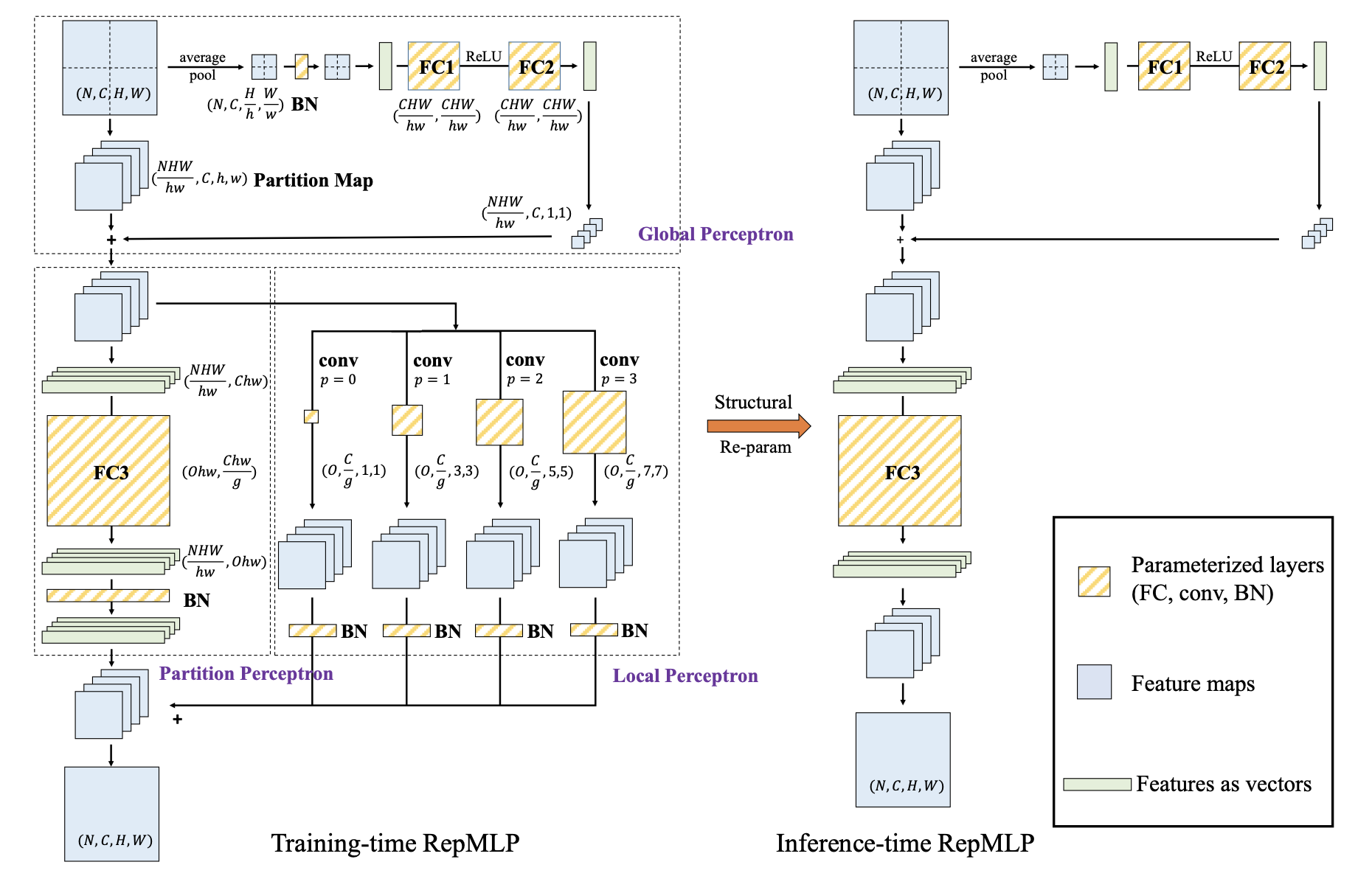
2-1. Formulation
본 논문에서, feature map은 tensor M으로 표기된다. F와 W는 conv 와 FC의 커널로 각각 사용하였다. 다음 formulation은 output feature map을 구한다. 다시말해, input feature map과 conv kernel 그리고 padding(p)을 convolution한 결과를 가진다.

FC를 위해서, P 와 Q는 input 과 output demension이 될 수 있다. V(in) 은 N * P demension을 가지고, V(out) 은 N * Q demension 이다. kernel W는 Q * P 이며, matrix multiplication(MMUL)은 다음과 같은 formulation을 가진다. RS(reshape) function을 사용했으며, 오직 tensor의 shape specification을 바꾼다. V(in)은 RS(M(in), (N, CHW)), V(out)(N,OHW)은 M(out)(N,O,H,W)로 reshaped back 된다.

2-2. RepMLP 구성 요소
본 논문들의 저자는 위에서 언급했다시피 local prior의 부족 뿐만 아니라 많은 parameter 갯수 때문에 FC를 사용하지 않았다. FC의 param 수는 COH^2W^2 이며 각 param은 H = 28, W = 28, C = 128, O = 128 이다. 이렇게 많은 param수를 줄이기 위해, Global Perceptron 과 Partition Perceptron을 제안한다.
Global Perceptron
feature map을 나눔으로써 다른 partition들이 parameters 을 공유할 수 있다. 예를들면, (N, C, 14, 14) 인풋을 (4N, C, 7 , 7)으로 나눌 수 있다. 이로써 모든 7 * 7 block 을 partition map으로 정의할 수 있다. input M은 (N, C, H/h, h, W/w, w)로 reshape 한다. 이 operation은 메모리 안에서 data를 이동할 필요가 없는 cost-free 이다.
이러한 방법으로 요구되는 param 수는 COH^2W^2 에서 COh^2w^2 로 줄어들게 된다.
그래서 Global Perceptron stage 순서는 다음과 같다. (이해하기 쉬우려면 위의 network overview 그림을 확인.)
1) 각 partition을 위한 pixel를 얻기 위해 average pooling을 한다.
2) 그것을 BN과 두 layer MLP를 통해 전이 시킨다.
3) reshape 한 (NHW/hw, C, 1, 1) 를 partition map (NHW/hw, C, h, w) 에 element-wise multiplication 힌다.
이러한 과정은 이미지를 split 하여 연산속도를 줄이면서 같은 채널의 다른 partition 사이의 correlation을 고려할 수 있다.
Partition Perceptron
Partition Perceptron stage에서는 크게 FC와 BN layer 구조로 이루워져 있다. 앞 과정 Global Perceptron 과정에서 나온 output (NHW/hw, O, h, w) 은 reshaped 되고, re-arranged 그리고 reshaped 한다. groupwise convolution 에 의해 FC3의 parameter를 줄인다. Groupwise convolution은 다음과 같다.

Partition Perceptron stage 순서는 다음과 같다.
1) V(in)을 spatial size 1 * 1 를 가진 feature map 으로 reshaping 한다.
2) g group을 가진 1 * 1 conv 으로 performing 한다.
3) V(out)으로 output feature map을 reshaping 한다.
이 groupwise matrix multiplication을 다음과 같이 나타낼 수 있다.

Local Perceptron
local perceptron 은 몇 개의 conv layers을 통해 partition map에 전이한다. conv 의 패딩은 resolution을 유지해야하기 때문에 구성되어야 한다. ( 본 논문에서는 p = 0,1,2,3 for K=1,3,5,7 로 구성)
마지막, 모든 conv branch들과 Partition Perceptron은 모두 element wise 한다. 이렇게 다른 kernel 사이즈를 줌으로써 local한 부분까지 네트워크가 배우게 된다.
2-3. Conv을 FC로 합치기 위한 Simple 하면서 Differentiable AIgorithm
조금 더 수식을 이해하기 쉽게 한번 알아보자. RepMLP 네트워크는 Global Perceptron 단계에서 FC 2개, Parition Perceptron 단계에서 FC 1개로 구성되어 있다. 이때 세가지 FC layers로 바꾸기 전에, conv 를 fc로 어떻게 합치는지 알아보자.
FC kernel은 W(1)(Ohw, Chw) , Conv kernel F(O, C, K, K) (K <= h,w) 이다. feature map M(in)에 FC kernel, Conv Kernel 을 각각 연산한 후 더하면 Conv 연산 결과와 FC 결과를 동시에 갖게 된다. 이를 통해 Conv 를 FC로 합칠 수 있다.

2-4. Converting RepMLP into Three FC layers
먼저 BN layer를 이전의 conv layer 와 fc3에 동등하게 융합시킴으로서 그것들을 제거하는 것이 필요하다.
다음 그림은 ResNet 네트워크에 결합하기 위해 디자인 된 RepMLP Bottleneck 구조이다.


Global Perceptron 안의 BN 또한 지워지는 왜냐하면 FC1에 들어가기 전에 affine transformation 을 적용하기 위해 동등해야 하기 때문이다.
2-5. RepMLP - ResNet
다음 figure 는 conv layer로만 구성된 네트워크(왼), 본 논문에서 제안하는 MLP 네트워크 (오) 차이를 나타내었다.


3. Experiment / Result
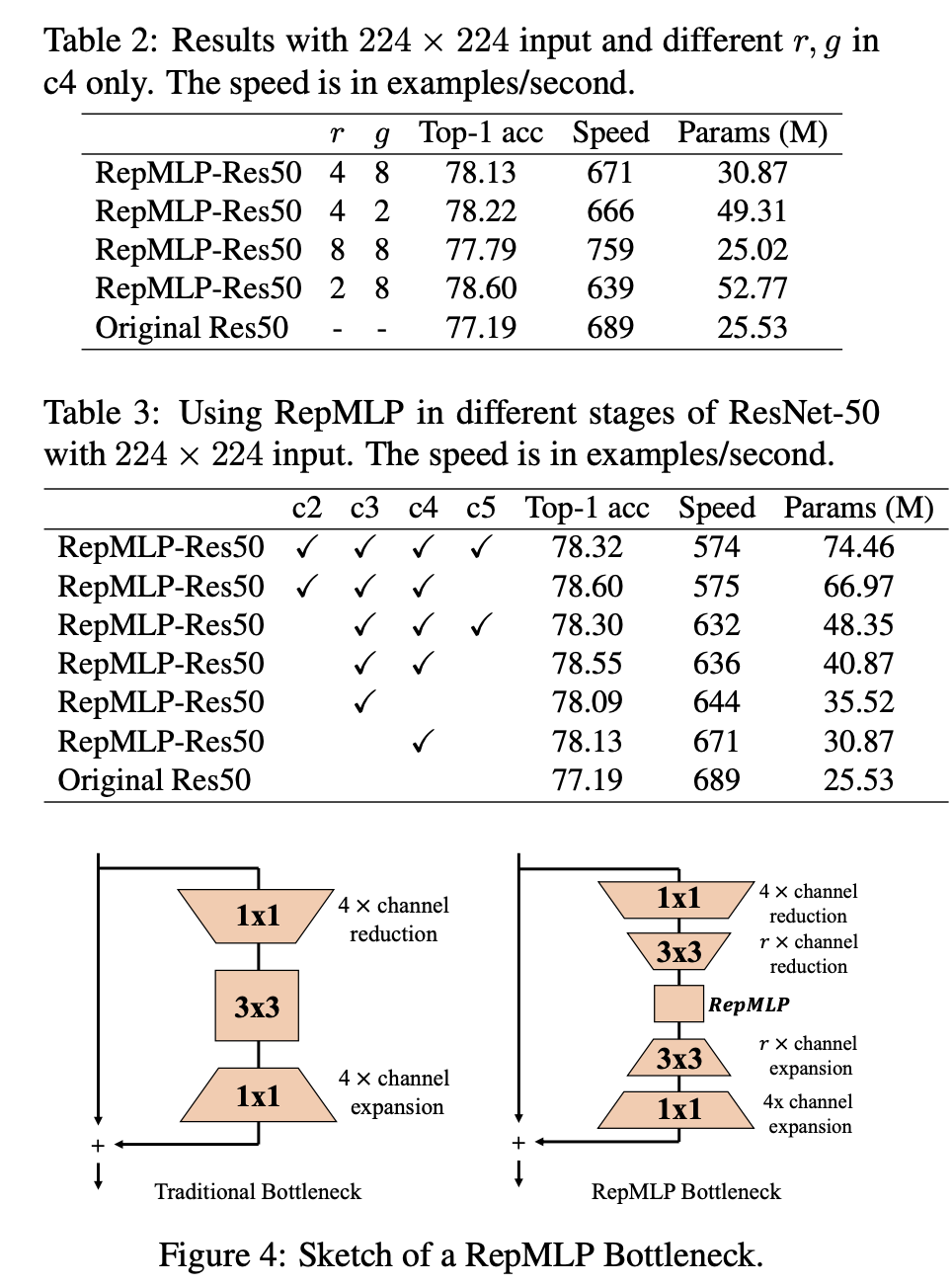
실험 결과, original Resnet 보다 계산 속도는 빠르며, accuarcy 도 향상된것을 볼 수 있다.
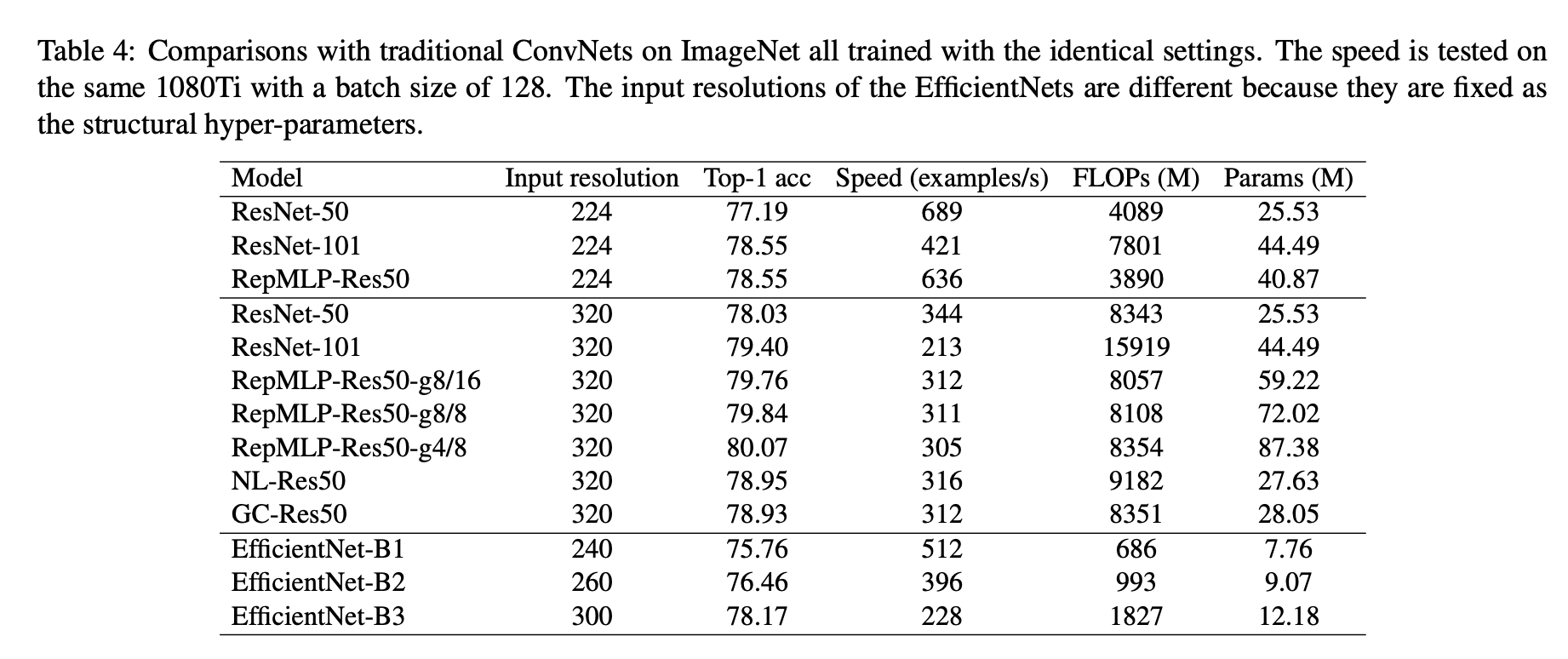
Resnet 뿐만 아니라 EfficientNet과 비교해도 계산 속도 측면에서도 빠르며, RepMLP-Res50 경우 비교 네트워크 중 가장 높은 정확도를 보인다.
[ Reference ]
- paper : https://arxiv.org/pdf/2105.01883.pdf
- pytorch code : https://github.com/DingXiaoH/RepMLP
'Artificial Intelligence > Research Paper 리뷰 📖' 카테고리의 다른 글
| [논문 리뷰] Free-Form Image Inpainting with Gated Convolution_ICCV 2019 (0) | 2021.10.31 |
|---|---|
| [논문 리뷰] Flow-edge Guided Video Completion_ECCV 2020 (0) | 2021.10.05 |
| [논문 리뷰] Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN_ICCV 2019 (0) | 2021.09.18 |
| [논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 2019 (0) | 2021.09.05 |
| [논문 리뷰] Domain Adaptation (0) | 2021.08.31 |
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
-
![[논문 리뷰] Free-Form Image Inpainting with Gated Convolution_ICCV 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FTisBE%2FbtrjvRwBEqS%2FPmZpU7J7iXEJqxaGgxgfnK%2Fimg.png) [논문 리뷰] Free-Form Image Inpainting with Gated Convolution_ICCV 20192021.10.31
[논문 리뷰] Free-Form Image Inpainting with Gated Convolution_ICCV 20192021.10.31 -
![[논문 리뷰] Flow-edge Guided Video Completion_ECCV 2020](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FkUzmn%2FbtrgDVjjXfp%2FuC1DYhzc3xvxWrrbxkxC7k%2Fimg.png) [논문 리뷰] Flow-edge Guided Video Completion_ECCV 20202021.10.05
[논문 리뷰] Flow-edge Guided Video Completion_ECCV 20202021.10.05 -
![[논문 리뷰] Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN_ICCV 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcptmCz%2Fbtrftor7NrV%2FBaxJg0TrZ0K5cOGueCFCh0%2Fimg.png) [논문 리뷰] Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN_ICCV 20192021.09.18
[논문 리뷰] Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN_ICCV 20192021.09.18 -
![[논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F5Ainn%2FbtrdJ3ECLYF%2FeV7LKoBsLXDKW8xnE4m3q1%2Fimg.png) [논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 20192021.09.05
[논문 리뷰] Deep Flow-Guided Video Inpainting_CVPR 20192021.09.05