
![[도서리뷰] 대학원생 때 알았더라면 좋았을 것들_엄태웅, 최윤섭, 권창현 지음.](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F28TWt%2FbtqR1DG7PKy%2F5kZyETdLmk945kUlKEkrIk%2Fimg.jpg)
같은 대학원생 친구의 적극 추천으로 읽게 되었다. 자신이 이 책을 대학원 진학 전에 읽었으면 얼마나 좋았을까 하면서.. 일단 이 책은 대학원생 또는 대학원을 준비하는 분들께 정말 도움이 될 것 같다. (대학원 재학중에 연구 주제를 정하기 어렵거나 대학원의 결정의 중요 순위를 결정하기에 도움이 될 듯하다.) 나 역시 석사 1기에 재학중이어서 첫 연구를 시작함에 어려움이 있지만 (사실 아직도 어려운것은 사실이다.) 이 책을 읽고 방향성에 도움을 받았다. 이 글을 읽는 분들도 한번 읽어보길 적극 추천한다. 글의 구성은 각 저자들의 스토리로 풀어 나간다. (e.g. 엄태웅 박사과정생편, 최윤섭 박사편, 권창현 교수편) 먼저, 가장 기억에 남는 최윤섭 박사편의 리뷰를 해보겠다. 세 박사님들과 KAIST학생들의 질..

본 개념은 Data Mining: Concepts and Techniques (Jiawei Han, Jian Pei, Micheline Kamber)서적을 바탕으로 합니다. 안녕하세요. 저번 포스팅에서는 닫힌 패턴과 최대 패턴에 관해 알아 보았습니다. 이번 포스팅에서는 빈발 패턴을 찾는 알고리즘을 조금 더 세부적으로 알아보겠습니다. 연관규칙 알고리즘을 효율적으로 탐색하기 위해서는 다양한 알고리즘이 적용될 수 있습니다. 효율적인 알고리즘이 왜 필요한가? 라는 질문엔 이렇게 답할 수 있겠습니다. 거래에서 나타나는 모든 항목들의 집합(item set)을 I 라고 할 때, 모든 가능한 부분집합의 개수는 공집합을 제외하고 M 개 입니다. 그리고 모든 가능한 연관규칙의 개수는 다음과 같습니다. 가능한 부분집합의..
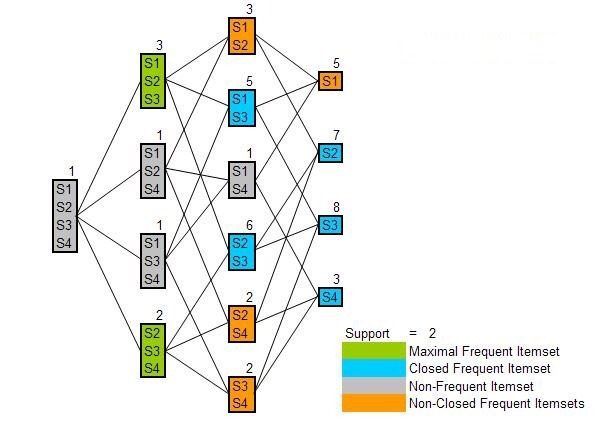
본 개념은 Data Mining: Concepts and Techniques (Jiawei Han, Jian Pei, Micheline Kamber)서적을 바탕으로 합니다. 저번 포스팅에서 Apriori와 FP-Growth를 보았습니다. 이번 포스팅엔 빈발 패턴을 구할 때 계산량을 줄이기 위한 알고리즘인 MaxMiner 과 CLOSET에 관해 알아보도록 하겠습니다. 설명하기 이전에 Closed Pattern과 Max-Pattern의 기본 개념에 관해 잠깐 알아보도록 하겠습니다. 아래는 Closed Pattern과 Max-Pattern을 잘 설명하는 그림입니다. *Closed Pattern : An itemset X is closed if X is frequent and there exists no s..

본 개념은 Data Mining: Concepts and Techniques (Jiawei Han, Jian Pei, Micheline Kamber)서적을 바탕으로 합니다. 안녕하세요. 컴공녀신 입니다. 오늘은 연관규칙 기법 중 유용하게 활용되는 Apriori 와 FP-Growth 알고리즘에 관해 알아보고자 합니다. # 1. Apriori Apriori 알고리즘 설명에 앞서 연관규칙에 관한 개념을 살~짝 짚고 넘어갈께요. 연관규칙이란 X->Y, X가 발생할 때 Y도 발생 할 경우를 의미합니다. 쉽게 설명하자면 {맥주}를 구매할 때 {기저귀}를 구매할 확률이 높습니다. 또한, {맥주, 기저귀, 땅콩 } 이 아이템 셋이 자주 발생한다면, {맥주, 기저귀} 또한 자주 발생합니다. 이렇게 어떤 두 아이템 집..

인코딩에 이어 데이터의 스케일링에 관해 알아보도록 하겠습니다. # 1. Feature Scaling (피쳐 스케일링) 이란. 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 피쳐 스케일링 (Feature Scaling)이라고 합니다. 대표적인 방법으로 표준화(Standardization)와 정규화(Normalization)가 있습니다. # 2. StandardScaler StandardScaler는 표준화를 쉽게 지원하기 위한 클래스입니다. 개별 피쳐를 평균이 0이고, 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것을 의미합니다. 수식은 다음과 같습니다. - numpy : z = (x - mean())/std() - scipy.stats : zscore() - sklearn.prep..
데이터 전처리(Data Processing or Cleansing)은 머신러닝 알고리즘 만큼 매우 중요합니다. 데이터 전처리 방법에는 다양한 방법들이 있는데요. 그 중에 문자열 데이터를 수치화 시켜주는 인코딩 방법과 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 피쳐 스케일링 (정규화, 표준화) 에 관해 실습해 보겠습니다. # 1. 데이터 인코딩 머신러닝을 위한 대표적인 인코딩 방식은 크게 레이블 인코딩(Label Encoding)과 원-핫 인코딩(One Hot Encoding) 방법이 있습니다. 1-1. 레이블 인코딩 사이킬런의 레이블 인코딩을 인포트 해옵니다. LabelEncoder를 객체로 생성한 후 fit() 과 transform()을 호출해 레이블 인코딩을 수행합니다. 각 문자열이 숫자로 ..

안녕하세요 :) 프록굥입니다. 오늘부터 "파이썬 머신러닝 완벽 가이드"를 바탕으로 머신러닝 실습을 해보며 정리를 해볼까 합니다. 실습하기 앞서 "파이썬 머신러닝 완벽 가이드" 책에 관해 살짝 언급하고 가자면, 본 책은 Kaggle에 있는 데이터들을 각 챕터에 나눠서 차근히 따라 해 보며 해 볼 수 있는 머신러닝 가이드 책입니다. 본 책의 가장 큰 장점이라면 정말 유용하게 쓰이는 다양한 기법들과 분석 pipeline 대로 Kaggle 대회를 그대로 실습해 볼 수 있는 점입니다. python 기초는 있는데 분석을 어떻게 해야 될지 모르시는 분들이나 조금 더 세부적으로 모델 성능 개선을 위한 기법을 정리하고 싶은 분들이 차근히 따라 해 보시면 좋을 것 같아요! 이 책의 가격은 3만 원 넘었던 것 같아요. 추천..