안녕하세요 :) 프록굥입니다.
오늘부터 "파이썬 머신러닝 완벽 가이드"를 바탕으로 머신러닝 실습을 해보며 정리를 해볼까 합니다.

실습하기 앞서 "파이썬 머신러닝 완벽 가이드" 책에 관해 살짝 언급하고 가자면, 본 책은 Kaggle에 있는 데이터들을 각 챕터에 나눠서 차근히 따라 해 보며 해 볼 수 있는 머신러닝 가이드 책입니다. 본 책의 가장 큰 장점이라면 정말 유용하게 쓰이는 다양한 기법들과 분석 pipeline 대로 Kaggle 대회를 그대로 실습해 볼 수 있는 점입니다. python 기초는 있는데 분석을 어떻게 해야 될지 모르시는 분들이나 조금 더 세부적으로 모델 성능 개선을 위한 기법을 정리하고 싶은 분들이 차근히 따라 해 보시면 좋을 것 같아요! 이 책의 가격은 3만 원 넘었던 것 같아요. 추천합니다!
이제 Chapter 1 부터 시작해 볼까요~
# 1. Basic Classification
우선, 필요한 라이브러리를 불러와줍니다. sklearn package 안에 iris 데이터가 내장되어 있습니다.
from sklearn.datasets import load_iris
import pandas as pd
import numpy as npiris = load_iris()
iris_data = iris.data #Xdata
iris_label = iris.target #target
iris_df = pd.DataFrame(iris_data, columns=iris.feature_names) #데이터프레임으로 변환
iris_df['label'] = iris.target #label이라는 컬럼 추가.
label 컬럼 안에는 iris의 종류가 0 1 2로 나눠져 들어가게 됩니다.
다음은 데이터를 train 과 test로 나눠서 훈련을 시킬 것입니다. 이를 위해 해당 라이브러리를 로드해줍니다.
train_test_split( X data, Target data, 테스트 비율, 랜덤 고정 시드 ) 순으로 옵션을 지정해 줍니다.
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(iris_data, iris_label,
test_size=0.2, random_state=777)
print(Xtrain.shape, Xtest.shape, ytrain.shape, ytest.shape) # 데이터 shape 확인
훈련은 DecisionTree Model로 해볼께요. 학습시킬 Training 데이터를 fit 해줍니다. 마지막으로 Test 데이터를 통해 예측값을 도출해 냅니다. 예측값은 pred 변수에 들어있겠네요!
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(random_state=777)
dt_clf.fit(Xtrain,ytrain) #학습
pred = dt_clf.predict(Xtest) #예측
끝난 게 아니죠. 실제 값과 우리가 예측한 값을 평가해보아야 얼마큼 우리가 맞췄는지 알 수 있겠죠?
이를 위해 sklearn 에 내장되어있는 분류 평가 지표 중 하나인 정확도(accuracy) 평가 라이브러리를 불러와서 평가해보죠.
from sklearn.metrics import accuracy_score
print("예측 정확도: {0:.2f}".format(accuracy_score(ytest, pred)))정확도가 1 이 나왔네요!!
사실 iris 데이터는 명확하게 피쳐 간 분류가 되기 때문에 정확도가 거의 1이 나옵니다.
# 2. Cross Validation (교차검증) : KFold
2-1. 교차검증을 사용하는 이유 ?
-
데이터 부족
-
Overfitting (과적합) 문제 해결
-
모델 평가
* 모델평가 :
새로운 데이터셋에 대한 모델의 성능을 미리 기존의 데이터내에서 나누어 훈련시키고 평가하여 추정하는 것.
즉, 모델의 일반화 오차에 대해 신뢰할 만한 추정치를 구할 수 있게 해주는 방법.
2-2. 교차검증의 종류?
-
Hold-Out (홀드아웃) ★
-
K-Fold Cross Validation (K겹 교차 검증) ★
-
Leave-P-Out Cross Validation / Leave-One-Out Cross Validation
-
Stratified K-Fold Cross Validation
저희는 여기서 2번째, 4번째 교차검증 실습을 해봅니다.
2-3. K-Fold란?
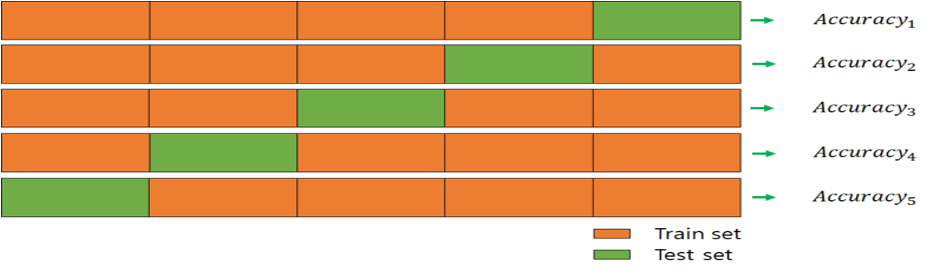

-
데이터셋을 k개의 서브셋으로 분리한다. k는 분리하고자 하는 폴더의 개수.
-
하나의 서브셋만 test에 사용하고 나머지 k-1개의 서브셋은 training에 사용.
-
이것을 k번 반복하고 각 성능지표에 대한 평균으로 최종적으로 모델의 성능을 평가한다
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5) #5fold
cv_accuracy = []
print('붓꽃 데이터 세트 크기:', iris_data.shape[0]) #행 출력(전체 데이터 갯수)
n_iter = 0
for train_idx, test_idx in kfold.split(iris_data):
Xtrain, Xtest = iris_data[train_idx], iris_data[test_idx]
ytrain, ytest = iris_label[train_idx], iris_label[test_idx]
dt_clf.fit(Xtrain, ytrain)
pred = dt_clf.predict(Xtest)
n_iter+=1
acc = np.round(accuracy_score(ytest, pred),2)
train_size = Xtrain.shape[0]
test_size = Xtest.shape[0]
print('\n#{0} 교차검증 정확도 : {1}, 학습 데이터 크기 : {2},
검증 데이터 크기 : {3}'.format(n_iter, acc, train_size, test_size))
cv_accuracy.append(acc)
print('\n=> 평균 정확도: {0}'.format(np.average(cv_accuracy))) #평균 정확도
#1 교차검증 정확도 : 1.0, 학습 데이터 크기 : 120, 검증 데이터 크기 : 30
#2 교차검증 정확도 : 1.0, 학습 데이터 크기 : 120, 검증 데이터 크기 : 30
#3 교차검증 정확도 : 0.9, 학습 데이터 크기 : 120, 검증 데이터 크기 : 30
#4 교차검증 정확도 : 0.93, 학습 데이터 크기 : 120, 검증 데이터 크기 : 30
#5 교차검증 정확도 : 0.8, 학습 데이터 크기 : 120, 검증 데이터 크기 : 30
=> 평균 정확도: 0.9260000000000002# 3. Stratified KFold
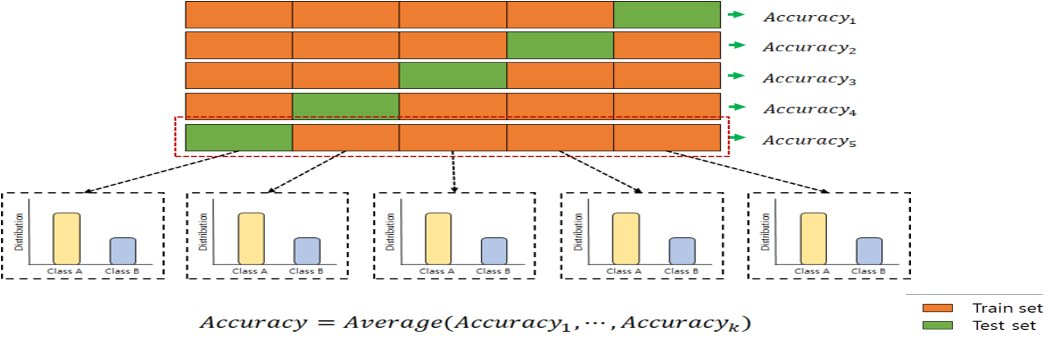
Stratified KFold는 주로 Classification 문제에서 사용되며, label의 분포가 각 클래스별로 불균형을 이룰 때 유용하게 사용.
불균형한 label 분포라는 말은 예를 들면 1000개 스팸 데이터를 분류해본다고 하죠. 우리가 예측해야 할 타깃이 스팸인지 아닌지라고 가정할 때 "스팸이 아니다"라는 라벨 값이 전체의 99%(990개) , "스팸이다"라는 라벨 값이 1% (10개)라고 하면 이를 5개의 Fold로 나눈다고 하면, 어떤 Fold에는 "스팸이 아니다"라는 라벨이 모두 들어 있을 확률이 높아집니다. 불균형한 상태로 교차검증을 하게되면 각 Fold 간의 정확도가 차이가 커질 뿐 만 아니라 학습의 효과가 없겠죠. 이를 위해 동일하게 라벨의 분포를 나눠줍니다. 5 Fold라고 가정하면 하나의 Fold에 "스팸이 아니다" 라벨이 198개, "스팸이다" 라벨이 2개씩 들어가겠네요. 즉, 데이터의 편향된 분포를 가져올 수 있기 때문에 label의 분포를 고려하여 나눠주어야 합니다.
from sklearn.model_selection import StratifiedKFold
StratifiedKFold = StratifiedKFold(n_splits=5) #5fold
cv_accuracy = []
for train_idx, test_idx in StratifiedKFold.split(iris_data, iris_label):
Xtrain, Xtest = iris_data[train_idx], iris_data[test_idx]
ytrain, ytest = iris_label[train_idx], iris_label[test_idx]
dt_clf.fit(Xtrain, ytrain)
pred = dt_clf.predict(Xtest)
n_iter+=1
acc = np.round(accuracy_score(ytest, pred),2)
train_size = Xtrain.shape[0]
test_size = Xtest.shape[0]
print('\n#{0} 교차검증 정확도 : {1}, 학습 데이터 크기 : {2},
검증 데이터 크기 : {3}'.format(n_iter, acc, train_size, test_size))
cv_accuracy.append(acc)
print('\n=> 평균 정확도: {0}'.format(np.average(cv_accuracy))) #평균 정확도가 kfold 보다 더 올라감
이상 교차검증에 관해 알아보았습니다. 도움이 되셨다면 댓글 및 하트 부탁드릴께요 :)
'Artificial Intelligence > Data Science' 카테고리의 다른 글
| Frequent Pattern Mining : Partition/ DHP/ Sampling/ DIC (0) | 2020.10.26 |
|---|---|
| Frequent Pattern Mining : CLOSET / MaxMiner (0) | 2020.10.25 |
| Apriori / FP-Growth Algorithm (0) | 2020.10.24 |
| 파이썬 머신러닝 완벽 가이드 - chap1-2. 데이터 전처리 (feat. 정규화/표준화) (1) | 2020.09.01 |
| 파이썬 머신러닝 완벽 가이드 - chap1-2. 데이터 전처리 (feat. 데이터 인코딩) (0) | 2020.08.29 |
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!