![[논문 리뷰] StyleCLIP - Text-Driven Manipulation of StyleGAN Imagery_ICCV 2021(Oral)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcZJbBA%2FbtrKmNvw1EL%2Fj5AAYcVtZkENKcxAKTK39K%2Fimg.png)

오늘 리뷰할 논문은 CLIP과 STLYEGAN2, 두 아키텍처를 이용한 text-driven image generation 논문이다. 본 연구는 text prompt에 따른 이미지 생성을 목표로 하며 본 논문에서는 3가지 테크닉을 제안한다.

1. text-guided latent optimization
하나의 이미지의 manipulation을 적용하기 위해 iteration으로 optimization 하는 방법. 변화는 잘 되지만 optimization을 위해 300 iteration 을 돌아야 하기 때문에 비효율적이다. 또한, disentanglement 가 안된다. 학습 loss는 다음 수식과 같다. G는 사전 훈련된 StyleGAN이다. GAN Generator 와 Dclip은 두 인수의 CLIP 임베딩 사이의 코사인 거리이다. 입력 이미지와의 similarity은 latent space의 L2 거리와 similarity loss에 의해 제어된다.
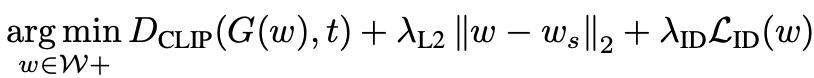
2. Latent Mapper
세부적인 text prompt 을 주고 latent residual mapper을 학습시킴. latent space 안에서 starting point (the input image to be manipulated)을 주고, mapper는 latent space안에서 local step을 함. 여기서 mapper는 한 텍스트당 각각 다른 mapper를 적용하였다. mapper는 각 feature level 에 따른 mapper로 나눠 학습시킨다. (그래야 섬세하게 face 의 특징을 나타내는 feature들을 학습시킬 수 있다고 한다. )

하지만 mapper의 한계점이 존재한다.
1. 빠른 inference time을 허용하지만, 미세하게 얽혀 있지 않은 조작을 원할 때 한계 있음. (얼굴이 미세하게 바뀜)
2. 주어진 text prompt에 대한 다른 조작 단계의 방향은 유사한 경향이 있다.


그래서 본 논문에서 텍스트 프롬프트를 StyleGAN Space S에서 single, global direction으로 매핑하는 방법을 제안한다고 한다.
3. Global mapping
StyleGAN의 style space에서 text prompt을 input-agnoistic(global) 방향으로 맵핑하는 방법. 이는 manipulation strength (알파)뿐만 아니라 disentanglement 의 degree (베타) 도 컨트롤 할 수 있다.

StyleGAN Space S는 다른 잠재 공간보다 disentanglement를 더 잘 함. s는 스타일 코드를 나타내고 G는 해당하는 생성된 이미지를 나타낸다.
1. 원하는 속성을 나타내는 텍스트 프롬프트가 주어지면, G(s + ∆s)가 다른 속성에 크게 영향을 미치지 않고 해당 속성이 도입되거나 증폭되는 이미지를 생성하도록 조작 방향 ∆s를 찾는다. 조작 강도는 α에 의해 제어됩니다. high level 아이디어는 먼저 CLIP 텍스트 인코더를 사용하여 CLIP의 공동 언어-이미지 임베딩에서 벡터 ∆t를 얻은 다음 이 벡터를 S에서 조작 방향 ∆s로 매핑하는 것이다. 안정적인 ∆t는 아래에서 설명하는 것처럼 신속한 엔지니어링을 사용하여 natural language로부터 얻어진다. 그런 다음 각 스타일 채널의 대상 속성에 대한 관련성을 평가하여 해당 방향 ∆s를 결정한다.
2. 좀 더 공식적으로, CLIP의 공동 임베딩 공간에서 이미지 임베딩의 매니폴드를 I로, 텍스트 임베딩의 매니폴드를 T로 나타낸다. 이들 사이에 일대일 매핑이 없기 때문에 이 두 매니폴드를 구분한다. 이미지는 단일 텍스트 문장으로 포괄적으로 설명하기 어려운 많은 시각적 속성을 포함할 수 있다. 반대로 주어진 문장은 많은 다른 이미지를 설명할 수 있다.
CLIP 훈련 동안 모든 임베딩은 unit norm으로 정규화되므로 임베딩의 방향만 의미 정보를 포함하지만 norm은 무시될 수 있다. 따라서 CLIP 공간의 잘 훈련된 영역에서 동일한 의미 변화에 대응하는 T 및 I 매니폴드의 방향은 대략적으로 동일하고(즉, 코사인 유사성이 크다) 정규화 후 거의 동일할 것으로 예상한다.
한 쌍의 이미지인 G(s)와 G(s+α)를 고려할 때, 각각 i와 i + αi로 그들의 I 임베딩을 나타낸다. 따라서 CLIP 공간의 두 이미지 간의 차이는 ∆i로 주어진다. ∆t로 인코딩된 자연어 명령이 주어지고 ∆t와 ∆i 사이의 공선성을 가정하면, S의 각 채널이 i 방향에 대한 관련성을 평가함으로써 조작 방향(manipulation direction) ∆s를 결정할 수 있다.
본 논문에서는 스타일의 강력한 생성력을 결합한 세 가지 새로운 이미지 조작 방법을 소개했다. 이러한 기술이 다양한 독특한 이미지 조작을 가능하게 하며, 그 중 일부는 프롬프트가 달린 데이터에 의존하는 기존 방법으로는 달성할 수 없다는 것을 보여주었다. 우리는 또한 CLIP가 원하는 헤어 스타일을 지정하는 것과 같은 세밀한 편집 제어를 제공하는 동시에 조작(manipulation) 강도(strength)와 분리 정도(degree)를 제어할 수 있다는 것을 입증했다.
'Artificial Intelligence > Research Paper 리뷰 📖' 카테고리의 다른 글
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
-
![[논문 리뷰] Segmentation-Free Dynamic Scene Deblurring (CVPR 2014)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcpTO2z%2FbtsjNN2i4o6%2Fg3Stqec1qN8092KQbuebt1%2Fimg.png) [논문 리뷰] Segmentation-Free Dynamic Scene Deblurring (CVPR 2014)2023.06.13
[논문 리뷰] Segmentation-Free Dynamic Scene Deblurring (CVPR 2014)2023.06.13 -
![[논문 리뷰] Side-Aware Boundary Localization for More Precise Object Detection (ECCV 2020)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbMu3IM%2FbtsiJ79g2bd%2F30zAzTURiWUASu4vZVB3wK%2Fimg.png) [논문 리뷰] Side-Aware Boundary Localization for More Precise Object Detection (ECCV 2020)2023.06.07
[논문 리뷰] Side-Aware Boundary Localization for More Precise Object Detection (ECCV 2020)2023.06.07 -
![[논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 2021](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FPlanM%2FbtrA6883Vfg%2F3JsiPxuaClswNsOMSAqt71%2Fimg.png) [논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 20212022.05.01
[논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 20212022.05.01 -
![[논문 리뷰] CycleMLP : A MLP-like architecture for dense prediction_ICLR 2022 (Oral)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FxOL8O%2FbtrviHW5ZsR%2FBUi8JSURjiwEtuBMJNFxK0%2Fimg.png) [논문 리뷰] CycleMLP : A MLP-like architecture for dense prediction_ICLR 2022 (Oral)2022.03.06
[논문 리뷰] CycleMLP : A MLP-like architecture for dense prediction_ICLR 2022 (Oral)2022.03.06