![[논문 리뷰] CycleMLP : A MLP-like architecture for dense prediction_ICLR 2022 (Oral)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FxOL8O%2FbtrviHW5ZsR%2FAAAAAAAAAAAAAAAAAAAAAEBw8mDvdSmcs34ONRyFCTX5mIZJnrVsvQqD9ZRjb8ju%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DjuO3cA6SmG8uCgzA5lx8JficNTk%253D)

오랜만에 논문 리뷰로 돌아왔다! (최근 블로그에 너무 소홀했음,, 이제 다시 열심히 정리해야겠다! 앗짜!!!)

최근 Transformer가 Vision분야로 넘어와서 다양한 task에서 SOTA를 찍었고, Transformer의 가장 핵심적인 아이디어인 self-attention이 이미지의 중요한 feature 정보를 파악하는데 용이하고, 또 cnn보단 조금 더 멀리 있는 feature 정보까지 파악할 수 있다는 점에서 많은 주목을 받았다. 그리고 이 후, self attention의 효과를 다양한 방법으로 시도하려는 연구가 많이 나오고 있다. 본 논문은 MLP 기반의 논문이며 self attention 대신에 fc(mlp)로만 self attention의 효과를 입증하는 논문이다.
CycleMLP가 나오기 이전에 MLP-like architecture 중에 가장 대표적인 모델이 바로 MLP-mixer이다. 2021년 5월에 나온 MLP-Mixer: An all-MLP Architecture for Vision 는 "ViT(Vision Transformer)의 self attention만으로 성능을 높일 수 있다면 MLP만으로도 성능을 높일 수 있지 않을까" 하는 질문에서 시작된 논문이다.
MLP layer 만으로 self attention보다 연산량은 빠르면서 더 나은 성능을 내서 주목을 받게 되었는데, 주목을 받게 된 이유는 크게 2가지로 말할 수 있다.
MLP mixer가 주목받을 수 있었던 이유
1. Linear computational complexity
ViT 모델은 self attention 기반의 모델이기 때문에 input 데이터의 모든 요소간의 관계를 계산하기 때문에 연산량이 quadratic O(N^2)하다. 하지만, MLP는 feature map H(Height)와 W(Width)를 곱하여 1차원 벡터로 flatten 시킨 후 계산한다. 그렇기 때문에 computational cost는 O(HW)라고 할 수 있다.
2. Lower inductive bias
inductive bias는 vit모델이 나오면서 나온 말인데, 학습과정에서 습득된 편향을 의미한다. ViT 나 MLP 모델은 CNN 보단 더 넓은 파라미터 스페이스를 가지고 있어서 더 적은 inductive bias를 가진다고 할 수 있다. 다시 말해, 모든 관계를 살펴보는 vit (self attention) 이나 mlp mixer (MLP) 가 위치 정보에 국한되어있는 cnn (local window) 보다 inductive bias가 더 적다고 할 수 있다.
MLP-Mixer은 image를 patch 단위로 쪼개고 patch를 임베딩 시킨 후 channel-mixing fc와 token-mixing fc를 번갈아 가며 사용한다. 하나의 토큰에 대한 channel mixing MLP는 1x1 conv로 채널간 연산을 수행하는 point-wise convolution(per location pixel mixing)과 동일한 역할을 수행하고, 다른 하나인 token-mixing MLP는 각 채널에 1x1 conv를 spatial에만 적용하는 depth-wise convolution(per spatial pixel mixing)과 동일한 역할이라고 할 수 있다. (그래서 mlp-mixer가 conv 과 동일한 역할을 한다라고도 한다.)


하지만 MLP Mixer layer의 첫번째 mlp인 token-mixing mlp은 spatial fc 연산을 하기 때문에 input size (HW *1 dim)에 제약이 걸린다. 매 layer마다 같은 resolution이 들어가야하기 때문에, 매 layer의 스케일을 달리 할 수도 없다. 다시 한번 mlp mixer의 drawback을 정리하자면 다음과 같다.
MLP mixer 단점
1. spatial fc 를 사용하기 때문에 input resolution이 고정되어야함.
2. computational complexity도 image size 에 quadratic하여 image size가 커지면 연산량이 너무 커짐.
3. 매 mlp layer마다 input size가 같아야하기 때문에 dense prediction에 적합하지 않다.
Cycle MLP는 MLP mixer의 단점을 심플한 방법으로 극복한 논문이다.
Methodolgy of Cycle MLP
Key Contribution
1. various image size를 다룰 수 있음. (spatial fc가 없음). 계층적 구조가 가능하기 때문에 dense prediction (e.g. object detection, segmentation)이 가능함.
2. local window를 사용함으로 linear computational complexity 를 달성. (fully spatial connection의 연산량 : O(N^2))
3. 기존 MLP-based model들과 SOTA transformer model (e.g. Swin Transformer) 보다 더 좋은 성능을 가짐.
그럼 Spatial FC가 무엇인가, 본 논문에서 제안하는 Cycle FC 연산을 어떻게 하는건가 알아 보도록 하겠다.
FC operator들 비교
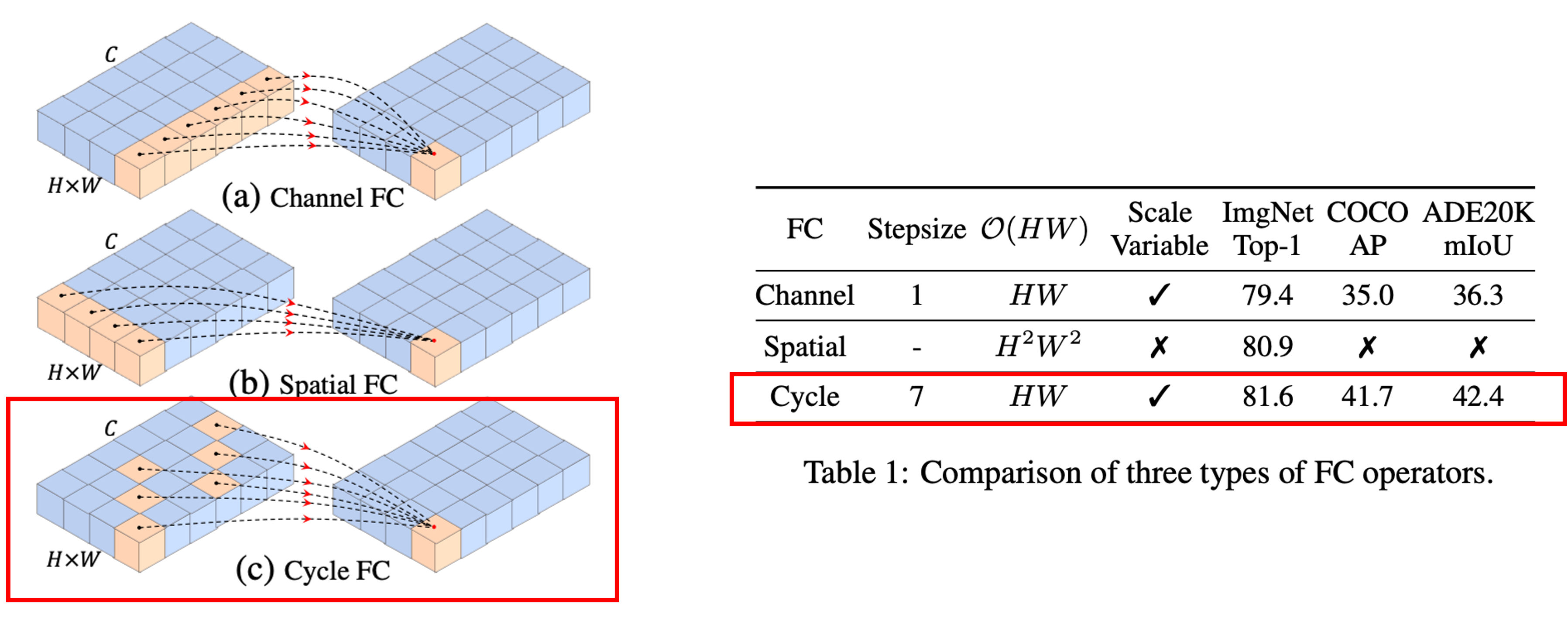
Cycle FC는 dense prediction task를 해결하기 위해 MLP-like model의 receptive field를 확장시킨 것이다. receptive field 역할을 수행하는( SH, SW )는 각 각 height와 width dimension에 따른 stepsize를 의미한다.
(a) Channel FC (channel mixing mlp과 동일)
하나의 point에 대한 모든 채널을 모아서 fc를 수행한 것.
(b) Spatial FC
한 채널에 대해서 h * w 를 fc 한 것. (token mixing mlp과 동일)
(c) Cycle FC
Channel FC형태인데 sampling하는 방법을 cyclic 하게 하여 fc를 수행한 것.
CycleMLP 연산 방법

그럼 CycleMLP 연산을 어떻게 수행할까? 일단, 그림이 보기 편하게 (d)~(f) tensor's width = 1 로 고정시킨 상태이다.
(d) SH=3, Sw=1
두 axis을 따른 offset이며 channel은 9이다. X는 feature 이고, 이해하기 쉽도록 인덱스화 시킨다.
결국엔, (i, j) 좌표의 feature map을 구하기 위해 9채널까지의 각 position((i,j)를 기준으로 offset값인 델타 i와 j를 더한 위치)에 해당하는 feature 값과 곱해서 더해주면 된다.

i,j (SH, SW) offset값을 구하는 notation은 다음과 같다.
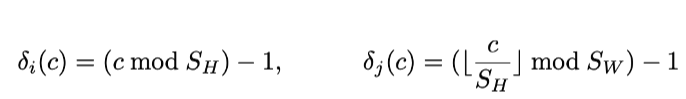
(e) SH=H, SW=1
global receptive field를 가짐.
(f) SH=1, SW=1
channel fc와 동일한 연산이라고 생각하면 된다.
Architecture Overall

1. Patch Embedding
- Overlapping patch embedding module (window size 7, stride 4) 사용
- feature map shape : H/4 × W/4 × C1
2. CycleMLP Block
- Three parallel CycleFC (stepsize S_H × S_w) : 1 × 7, 7 × 1, 1 × 1 (Inspired by the Criss cross attention)
(stepsize를 7로, three parallel 1 × 7, 7 × 1, 1 × 1 로 한 이유는 ablation study에 추가로 나와있으니 논문을 참고하면 좋을 듯하다.)
3. Model : hierarchical architecture (4 stage)
- output feature shape at the last stage : H/32 × W/32 × C_4.
-PVT (pyramid vision Transformer) style
-Swin style
(dense prediction에 용이한 피라미드 형태의 transformer의 구조를 그대로 사용함. attention layer를 cyclemlp 로 변경하였음.)
Experiment
CycleMLP로 다양한 실험을 진행하였다.
1. 1K-ImageNet Classification
왼쪽 테이블은 다른 MLP-like model과의 비교 테이블이고, 오른쪽 테이블은 다른 SOTA 모델과의 비교 테이블이다.

2. Object detection / Instance Segmentation

3. Semantic Segmentation / Robustness
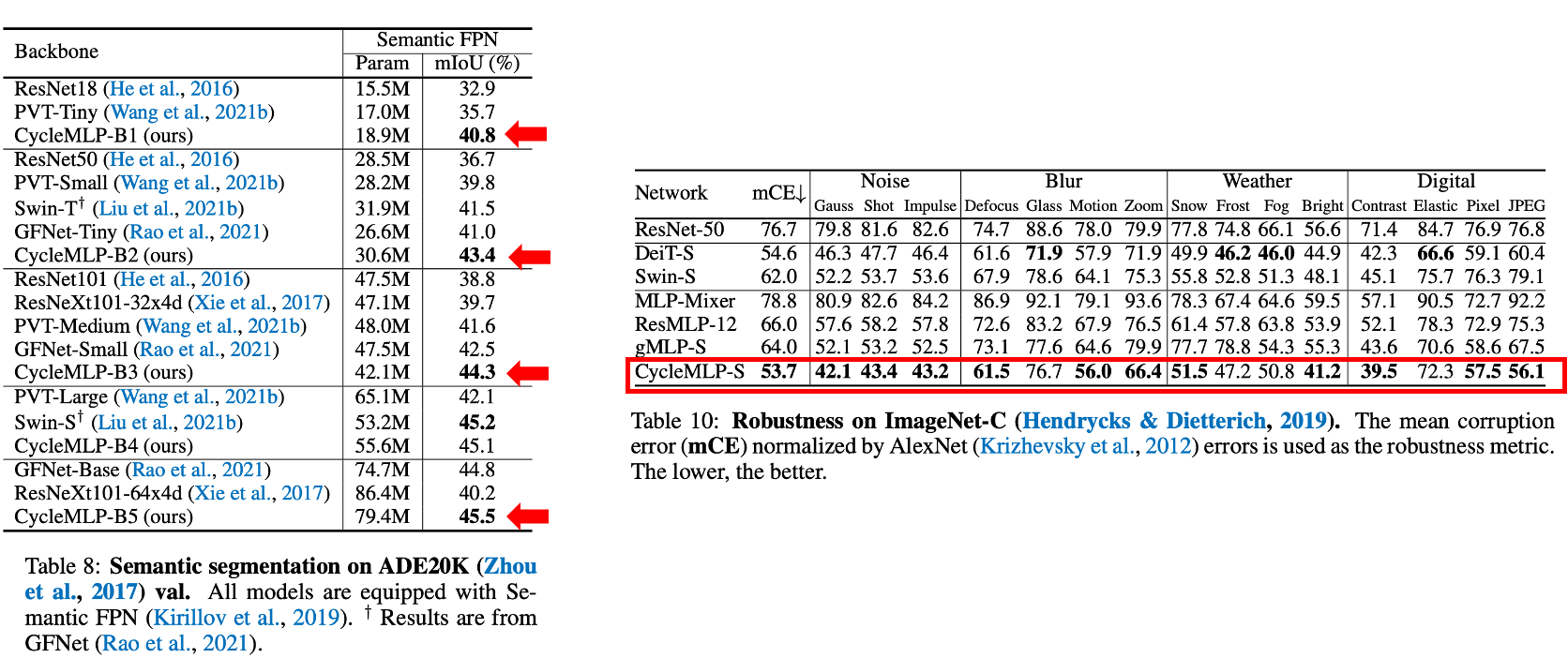
다양한 실험에서 기존 sota모델 대비 더 좋은 모델 성능을 가진다.
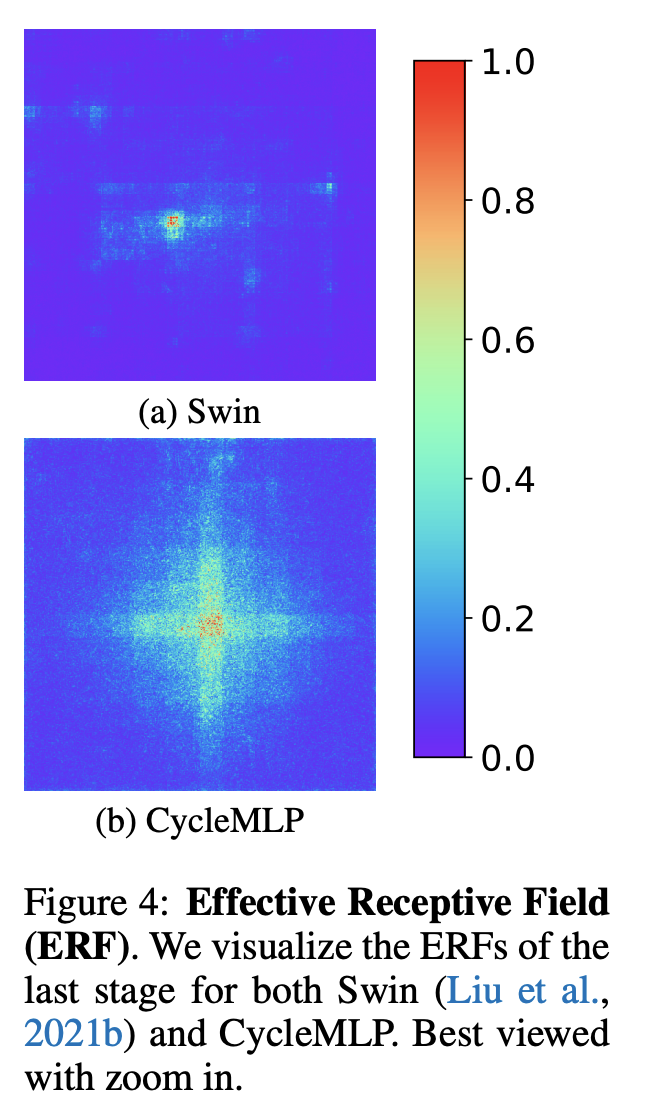
추가로 조금 신기했던 부분은 Swin Transformer와 Cycle MLP의 receptive field 비교이다. Cycle MLP가 Swin 모델보다 더 큰 receptive field를 가지는 것을 볼수 있다.
Conclusion
1. CycleMLP는 유연한 입력 resolution에 대처할 수 있는 computational friendly한 연산을 가진다.
2. dense prediction을 위해 Cycle FC 연산자를 기반으로 하는 계층적 MLP like model(CycleMLP)를 구축하기 위한 첫 번째 시도임.
3. 파라미터 수를 늘리지 않고 receptive field를 늘린다.
리뷰를 마치며..
mlp가 self attention의 성능을 뛰어넘을 뿐만 아니라 연산량 측면에서도 굳이 query key value를 가지고 복잡한 연산을 할 필요가 없다는 점이 매우 흥미로웠다. 또한, vision 분야에서 cnn의 localization이 모델이 이미지의 feature를 뽑아내는데 중요하게 작용했지만 이제는 fc layer로만으로도 feature를 충분히 캡쳐할 수 있다는 부분이 한번 더 주목받을 만하다. 또한, CycleMLP가 이전 MLPMixer 처럼 spatial fc를 사용하지 않고, cyclic한 패턴으로 feature를 가지고 fc 연산을 하기 때문에 input resolution에 제약을 받지 않으면서도 channel fc보다는 더 넓은 receptive field를 가질 수 있다는 점이 큰 장점이라고 생각한다.
CycleMLP paper : https://arxiv.org/pdf/2107.10224.pdf
'Artificial Intelligence > Research Paper 리뷰 📖' 카테고리의 다른 글
Action speaks louder than words. 하루 하루의 기록을 습관화 합니다 📖
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
-
![[논문 리뷰] StyleCLIP - Text-Driven Manipulation of StyleGAN Imagery_ICCV 2021(Oral)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcZJbBA%2FbtrKmNvw1EL%2FAAAAAAAAAAAAAAAAAAAAAAlYWPtlJ_vEPjbVUNNRIYHBd1JO1KZk_4i666uVsNeR%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3D8Rou7ssc%252BmjyWluWvuk2z6symTU%253D) [논문 리뷰] StyleCLIP - Text-Driven Manipulation of StyleGAN Imagery_ICCV 2021(Oral)2022.08.23
[논문 리뷰] StyleCLIP - Text-Driven Manipulation of StyleGAN Imagery_ICCV 2021(Oral)2022.08.23 -
![[논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 2021](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FPlanM%2FbtrA6883Vfg%2FAAAAAAAAAAAAAAAAAAAAABDe3H0yDRAcO0BP50m5Bhgc6EZ6UgTpuNOtDNkZD_tT%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DEzHPCoJUzyMcRD4ps1Ob7TKSojY%253D) [논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 20212022.05.01
[논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 20212022.05.01 -
![[논문 리뷰] Learning to Paint With Model-based Deep Reinforcement Learning_ICCV 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F3FohT%2FbtrlUNFYQbX%2FAAAAAAAAAAAAAAAAAAAAADheoJ2N52HALpq3PYaqS1px2r9mnLYD2XrhP9PgXv-b%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3D3WvVZxtGWYCYG%252BskcXKTHYIzua4%253D) [논문 리뷰] Learning to Paint With Model-based Deep Reinforcement Learning_ICCV 20192021.11.23
[논문 리뷰] Learning to Paint With Model-based Deep Reinforcement Learning_ICCV 20192021.11.23 -
![[논문 리뷰] Free-Form Image Inpainting with Gated Convolution_ICCV 2019](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FTisBE%2FbtrjvRwBEqS%2FAAAAAAAAAAAAAAAAAAAAAGUPwPQmFUPo3ncy_q7HB-dboeugR6I6iROsWzf0jPA2%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DnwGeVoELtiiboZ224ABlsXtVSp4%253D) [논문 리뷰] Free-Form Image Inpainting with Gated Convolution_ICCV 20192021.10.31
[논문 리뷰] Free-Form Image Inpainting with Gated Convolution_ICCV 20192021.10.31