

Gaegul's devlog
[논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 2021 본문
[논문 리뷰] TediGAN: Text-Guided Diverse Face Image Generation and Manipulation_CVPR 2021
부지런깨꾹이 2022. 5. 1. 22:44안녕하세요! 오랜만에 돌아온 논문 리뷰 입니다.

오늘은 요즘 핫한 text to image generation task의 cvpr 21 에 어셉된 페이퍼인 TediGAN을 리뷰하고자 합니다!
TediGAN의 주된 테스크는 다양한 가이드 (e.g. sketch, semantic label, textual description)를 컨디션으로 주면 이미지 synthesis에 포커싱하여 생성하는 것 입니다.
본격적으로 설명하기 앞서 TediGAN의 베이스 모델인 StyleGAN에 대해 살짝 알고 가면 좋을 것 같아 설명해보려 합니다!

StyleGAN은 input vector z로 부터 직접 이미지를 생성하는 것이 아니라, mapping network을 거쳐 intermediate vector W로 먼저 변환한 후 이미지를 생성한다. z로 feature를 매칭하게 되면 input distribution에 제한이 된다는 한계점이 있다. 하지만, mapping network를 사용할 경우, w는 고정된 distribution에 따를 필요가 없어지기 때문에, 학습 데이터를 훨씬 유동적인 공간에 맵핑하여 왜곡된 부분을 더 넓고 다양하게 표현할 수 있다. 이것을 disentanglement라고 하며, feature가 얽혀있다라고 한다.
StyleGAN의 핵심적인 layer는 AdaIN 이다. AdaIN은 이미지를 생성할 때 각각의 스타일이 입혀진다(e.g. 머리카락, 얼굴, 색상) 라고 하는 가정에서 나온 layer이다. 채널단위로 정규화를 수행하고 별도의 스타일 정보를 입력 받아서 feature 상의 statistic 을 바꾸는 방식으로 스타일을 입힌다. 이때 latent vector인 W는 affine transformation을 거쳐서 AdaIN에 들어가는 스타일 정보를 만든다. 각 컨볼루션 레이어에서 가우스 노이즈는 비선형성을 평가하기 전에 각 컨볼루션 후에 추가된다. 여기서 "A"는 학습된 affine transformation을 의미하며, "B"는 학습된 채널당 스케일링 인자를 노이즈 입력에 적용한다. Mapping Network f는 8개의 계층으로 구성되며 synthesis network g는 각 해상도에 대해 2개의 계층으로 18개의 계층으로 구성된다. 마지막 레이어의 출력은 별도의 1 × 1 컨볼루션으로 RGB로 변환된다.

생성 네트워크는 4x4x512 constant tensor를 convolution, upsampling을 통해 1024x1024x3 이미지로 변환시킨다. 이 때 각 convolution layer 이후마다 AdaIN을 통해 style이 입혀진다. 이로서 특정 layer에서 입혀진 style은 바로 다음 convolution layer에만 영향을 끼치며, 각 layer의 스타일이 특정한 속성만 컨트롤하게 된다.
Syntheisis Network의 중간 들어가는 랜덤 노이즈는 stochastic한 정보를 따로 주어 더욱 사실 적인 이미지를 생성할 수 있고, 다양한 확률적인 측면을 컨트롤 할 수 있다. 이렇게 stochastic한 정보를 따로 추가해주면 더욱 사실적인 이미지를 생성하게 될 뿐 아니라, input latent vector는 이미지의 중요한 정보(성별, 인종, 헤어스타일 등)를 표현하는 데에만 집중할 수 있게 되고 이를 조절하는 것도 더욱 쉬워진다.

본 논문은 입력되는 layer의 위치에 따라서 해당 style이 구분된다고 말한다. Latent Vector는 18 x 512 차원의 행렬 벡터이다. 앞쪽 4개의 latent vector가 coarse style, 그 다음이 middle이며, 다음은 조금 더 정교한 이미지를 생성하기 위한 fine style을 담당한다.
TediGAN

Methodology
1. StyleGAN Inversion Module
StyleGAN Inversion의 목적은 image encoder를 real image가 FFHQ dataset으로 pretrained한 StyleGAN 모델의 latent space로 맵핑될 수 있도록 하는 것이다. inversion을 위한 우리의 목표는 픽셀값으로 부터 input image를 reconstruct 하는 것 뿐만 아니라, semantically하게 의미있고, 해석가능한 inverted code를 얻는것이다.
GAN 모델은 일반적으로 가짜 이미지를 만들기 위한 생성기 G(·) : Z → X와 합성된(synthesized) 실제 데이터를 구별하기 위한 판별기 D(·)로 구성된다. 반대로, GAN inversion은 주어진 이미지 x를 잘 훈련된 잠재 공간으로 반전시킴으로써 최고의 잠재 코드 z를 찾기 위한 inverse mapping을 연구한다. 일반적인 해결책은 Ev(·) : X → Z (문자 v는 시각적인 것을 의미한다.) 와 같이 추가 인코더를 훈련시키는 것이다. 구체적으로, 잠재 코드 z의 집합은 먼저 prior distribution(예: 정규 분포)으로 부터 랜덤하게 이루어진다. 그리고 zs를 통해 xs를 훈련 쌍으로 얻기 위해 G(·)에 전달한다. Ev(·)는 xs와 zs를 각각 입력 및 감독으로 사용하며 다음과 같이 훈련된다.
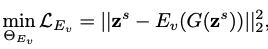
기존 프레임워크와 비교했을 때 두 가지 주요 차이점이 있다. (a) 인코더는 합성된 이미지보다는 실제 이미지로 훈련되어 실제 애플리케이션에 더 적합하다. (b) 재구성은 의미론적 지식과 정확한 감독을 제공하고 통합이 가능한 잠재 공간 대신 이미지 공간에 있다. Perceptual loss및 LPIPS와 같은 강력한 image generation loss의 합친다. F(·)는 VGG feature extraction model을 의미한다.
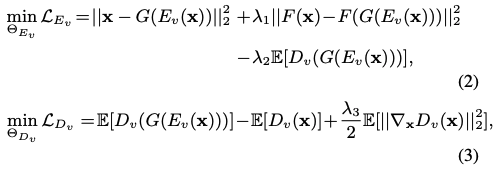
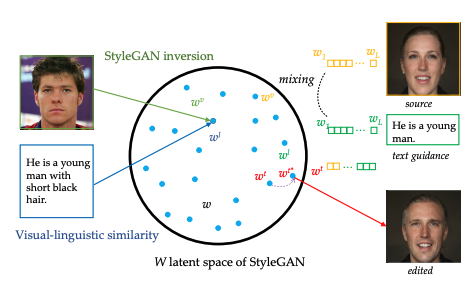
학습된 이미지 인코더를 통해, 우리는 실제를 W공간에 이미지를 투사한다. 획득한 코드는 스타일의 의미 도메인과 정렬되도록 보장된다. GAN 생성기 및 이미지 텍스트 인스턴스 쌍 간의 교차 모달 유사성을 채굴하는 데 추가로 사용될 수 있다.
2. Visual-Linguistic Similarity Learning
Inversion 모듈이 훈련되면 실제 이미지가 주어지면 StyleGAN의 W 공간에 매핑할 수 있다. 하지만, 다음 문제는 어떻게 텍스트 인코더를이미지와 텍스트를 alignment하게 훈련시키느냐는 것이다. 이를 위해 본 논문에서는 text의 latent code와 image latent code의 alignment를 위해 두 코드의 거리를 최소화 하도록 Visual-Linguisstic Similarity learning l2 loss 를 제안한다.
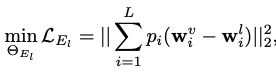
3. Instance-Level Optimization
face manipulation의 메인 첼린지는 identitity preservation(아이덴티디 보존)이다. 제한된 representation capability 때문에, encoder 혼자 완벽하게 reverse mapping 을 하는 것은 쉽지 않다.
최근 방법 (기존) : identitity를 보존하기 위해, ouput image 와 그것의 source image에 대한 cosine similarity를 측정하기 위한 face recognition loss를 도입하는 것이다.
조정된 z*를 위한 최종 loss 는 다음과 같다.

첫번째 Term은 manipulate을 하기 위한 original image(=source image) x와 z로 Inverse 생성한 output image G(z) 사이의 l2 loss 이며, 두번째 Term 은 생성된 이미지의 feature와 원래 이미지의 feature 사이의 l2 loss를 구하는 perceptual loss이다. 마지막 Term은 z와 z를 generator에 넣어 나온 이미지를 다시 encoder에 넣어 나온 z의 l2 loss regularization이다.
4. Control Mechanism
Attribute-Specific Selection
본 논문의 메커니즘은 StyleGAN의 stylemixing를 베이스로 만듬. StyleGAN의 layer-wise representation은 sementic fragment(속성 또는 물체)의 disentanglement를 배운다. wc와 ws는 각가 content code이고, style code이며, 이 control mechanism 은 attribute-specific layer이고, wc의 corresponding layer로 대체 됨으로써 ws의 layer와 mix 될 수 있다.
For text-to-image generation : 텍스트-이미지 생성을 위해 생성된 이미지는 텍스트 설명과 일치하므로 wc는 언어 코드이며, 다양성을 제공하기 위해 ws와 같은 크기로 무작위로 추출된 latent code 이다.
For text-guided image manipulation : text-guided image manipulation 경우 wc는 visual 임베딩이고 ws는 lingustic 임베딩이며, 혼합을 위한 레이어는 관련 속성만 수정하고 관련 없는 속성을 변경하지 않도록 하기 위해 텍스트와 관련이 있어야 한다.
Supported Modality

스타일 코드와 컨텐츠 코드 ws와 wc는 그림과 같이 스케치, 레이블, 이미지 및 노이즈일 수 있으며, 이는 TediGAN이 다중 모달 이미지 합성을 가능하게 한다. 그림과 같이 Control Mechanism으로 인해, 본질적으로 설명이 있는 스케치(Sketch) 및 의미 레이블(Label)에 대한 연속 연산 및 멀티 모달 합성도 가능하게 한다.
다양한 결과를 내기 위해 텍스트와 관련된 레이어를 변경하지 않고 무작위로 샘플링된 잠재 코드로 대체하는 것이다. 텍스트 가이드를 사용하여 다른 촬영장비에서 이미지를 생성하려면 스케치를 예로 들어 실제 이미지 인코더를 훈련하는 것과 동일한 방식으로 추가 스케치 이미지 인코더 Evs를 훈련시키고 다른 부분은 변경하지 않은 상태로 둘 수 있다.
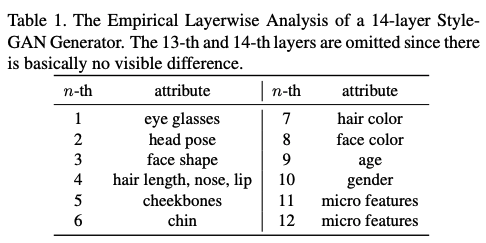
Layerwise Analysis
본 실험에서 사용하는 pretrained StyleGAN은 14 layer를 다루며, 256*256 image를 생성한다.
- 초반 layer (4*4 or 8*8) 는 안경 또는 head pose를 다룬다.
- 중간 layer (16*16 or 32*32)는 헤어 스타일이나 얼굴 표현을 다룬다.
- 끝 쪽 layer (64 * 64 or 1024*1024)는 색상이나 세부적인 디테일을 다룬다.
- 마지막 11-14 layer 는 초미세 디테일(e.g. 주름, 모공)을 나타낸다.
Experiment
Dataset
Multi-Modal CelebA HQ 이며, 30,000 개의 high resolution face 이미지이며, 각각은 high quality segmentation mask, sketch, 그리고 descriptive text를 가진다.

Model
image generation 비교를 위한 sota 모델은 AttnGAN, ControlGAN, DM-GAN, DFGAN 이다. 그리고, image manipulation비교를 위한 sota 모델은 ManiGAN을 사용했다.
Result
이미지 퀄리티를 위한 평가 지표는 FID와 LPIPS를 사용하였으며, text에 맞게 생성된 이미지에 대한 정확도를 측정하였다.
1) Text to Image Generation

2) Text-Guided Image Manipulation

이를 통해 본 논문에서 제안하는 TediGAN 이 다른 sota 대비 좋은 성능을 나타내고, 최고의 품질, 다양성, 사진 현실성 및 텍스트 관련 이미지를 생성할 수 있음을 증명한다.
Conclusion
text guided image generation 및 manipulation을 동일한 프레임워크로 통합하고 얼굴 이미지 생성 및 조작에 대한 높은 접근성, 다양성, 제어성 및 정확성을 달성하는 텍스트 설명을 이용한 새로운 이미지 생성 방법을 제안하였다. 제안된 다중 모드 GAN Inversion 및 대규모 다중 모드 데이터 세트(scketch, label)를 통해 품질의 이미지를 효과적으로 생성할 수 있다. 광범위한 실험 결과는 이미지 합성 효과, 고품질 결과 생성 능력, 다중 모드 입력에 대한 확장성 측면에서 우수성을 입증한다.
논문 리뷰를 마치며..
본 논문은 StyleGAN Inversion을 통해 이미지를 생성하고, latent code 조작한다. text 와 image 의 임베딩 z를 잘 alignment해서 높은 퀄리티의 이미지를 생성하는 결과는 대단하다고 생각한다.
하지만, 아쉬운 부분으로써는 StyleGAN에 관련된 잠재적 문제를 언급하였는데 첫번째는 텍스트 설명에 따라 주어진 이미지를 조작할 때 일부 관련이 없는 속성이 원치 않게 변경된다는 것을 발견했다고 한다. 이는 애초에 visual-lingulistic 학습의 문제일 수 있다고 생각했지만, 두 실제 이미지의 inverted code에서 layer별 스타일을 혼합할때 여전히 간섭이 존재한다고 한다. 이는 다른 속성이 직교(다른 속성에 영향을 미치지 않는 의미)여야 하는 W 공간에 일부 얼굴 속성이 얽혀 있다는 것을 의미한다. 스타일에 내재된 또 다른 결함은 모자, 목걸이, 귀걸이와 같은 일부 속성이 잠재 공간에 잘 표현되지 않기 때문에 text를 통해 악세서리를 지우고 생성할때 잘 되지 않는다고 한다.
이런 specific한 부분까지 latent에 잘 맵핑되면 더 섬세한 text guide까지 가능할 것이라 생각하지만, 이를 위한 방법은 조금 더 연구 해봐야 할 것으로 판단된다.
이상 끝 -!
paper : https://openaccess.thecvf.com/content/CVPR2021/papers/Xia_TediGAN_Text-Guided_Diverse_Face_Image_Generation_and_Manipulation_CVPR_2021_paper.pdf



